<Cassandra-based 的設計模型:Chebotko Diagrams>

Index
前言
這篇文章會翻譯和整理一篇論文 <A Big Data Modeling Methodology for Apache Cassandra>,這篇論文是由維護 Apache Cassandra 商用版 DataStax 的工程師所寫的論文 (發表在 2015 IEEE BigDataCongress 上)。
我個人認為非常適合做為學習 Cassandra 這種系統的基石 (如果有經驗一點的讀者會發現 Google BigTable 和 AWS 的 DynamoDB 都可以適用本論文的概念)。
特別注意!這篇論文不是講解怎麼安裝或是使用 Cassandra,而是提出一種 Cassandra 專用的方法論來 Model Cassandra,就像是如果你要學 Relational Database 會要知道 ER Model 和 Normal Form 這些方法,而這篇論文主要的貢獻就是提出一套可行的方法論來供我們設計系統。
先備知識
由於 Cassandra 是屬於較新時代的 Database,所以這篇論文會提出很多比較 Relational Database 設計上的同異之處,所以至少建議讀者要有以下的觀念:
- ER Model (Entity-Relation)
- Normal Form (3rd Normal Form)
- 一些 SQL 基礎的語法的觀念
目標
相信各位如果到這裡還沒關掉文章,應該是已經很熟悉 Relational Database 但又想看看新的東西有什麼有趣的,作者一開始就指明,千萬不要把 Relational Database 那套想法搬過來直接用!
Relational Database 的思考方式是以資料為中心,會先構思 Entity 和 Relation 之間作為基礎,用 Normal Form 去規範資料的重複性。但是 Cassandra 是一個特化的系統,設計上已經專門為特定的 Query 做優化,所以需要用全新的方法來思考。
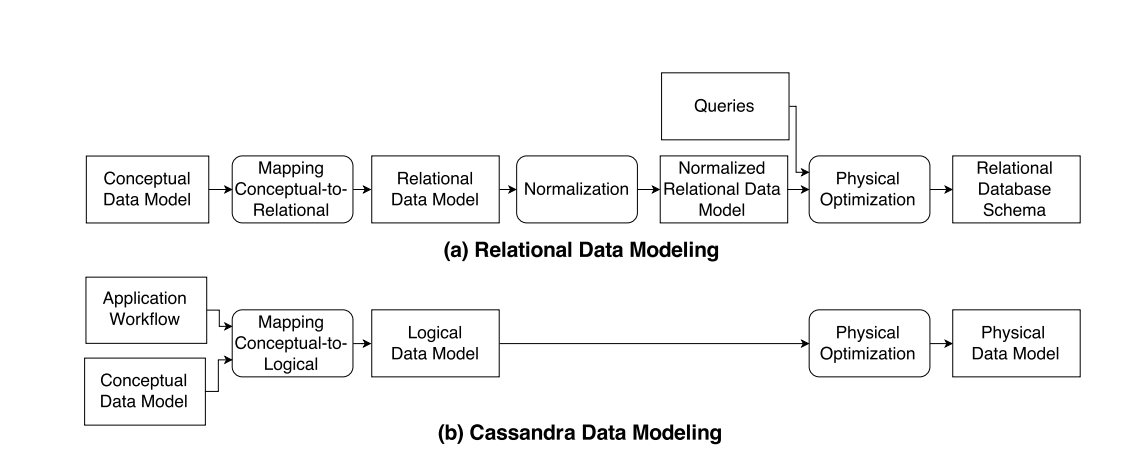
以上是兩者之間的差距,這篇論文就是在描述這兩種設計方式的差異,詳細我們就繼續看下去吧!
Cassandra’s Data Model
我們就從 Cassandra 的 Data Model 開始介紹吧!Cassandra 的和所有的 Database 一樣都有 schema。
Keyspace
最上層的叫做 keyspace,負責管理許多 Cassandra Table,讀者可以類比成 Relational Database 的 DATABASE。
Table
注意!這裡開始就和 Relational Database 有很大的不同了!
- Cassandra Table 由 partition 構成,partition 之中又有包含 row
- 每一個 partition 都會有一個 唯一的 partition key
- 每一個在 partition 之中的 row 又可以可選擇性的有唯一的 clustering key
- 上面的說的 key 都可以由單行或是多行的 row 組成
- partition key 和 clustering key 組成的叫做 primary key
- rows 都會依照 clustering key 來做排序 (ascending/descending)
- 所有的 column 可以是常見的 data type 或是使用者自定義的結構
- 唯一特別的 column data type 叫做 counter,主要用來處理 concurrent transaction
小觀察 1:由於 clustering key 是可以選擇不要,這個時候 primary key 就是 partition key
小觀察 2:有 clustering key 的 Table 就有 multi-row partitions
我相信各位一定跟我一樣,看到這裡頭早就昏掉了(QQ),到底在公三小 xD。
所以作者有幫我們舉出實際的例子,我們可以先看一下實際例子,再回頭看看這些規則!
Table Example:single-row partitions
首先這個例子是介紹 single-row partitions table,artifacts 明顯是名稱,這個表中只有 partition key,由於 partition key + clustering key = primary key,所以 primary key 就是 artifact_id。

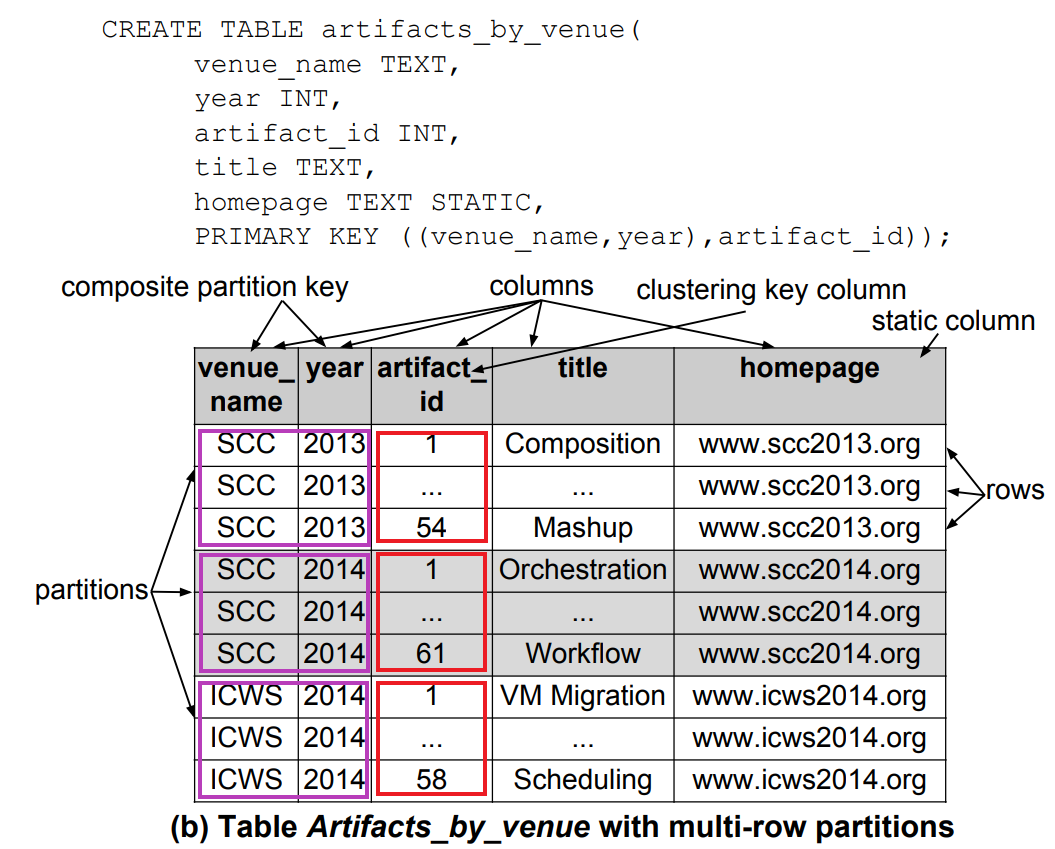
Table Example:multi-row partitions
這個例子則是 multi-row partitions table,artifacts_by_venue 這張表用 (venue name, year) 組成 partition key (紫色框框)。
clustering key 則是 artifact id。我們可以看到有三個不同的 partitions 裡面都有很多rows,如果我們檢查 每一個 partition 就會發現 rows 的順序會照 clustering key 排序 (紅色框框)。
Query Model
接下來我們介紹 Cassandra 的 Query,取名叫做 CQL,雖然模擬 SQL,但是卻沒有所有 SQL 的特性,例如:沒有 JOIN。以下是一些 Query 的原則:
- 只有 primary key 可以放在 query predicate
- partition key 一定要 filter (例如:equality search)
- clustering key 你可以自由使用在 predicate
- 如果 clustering key 被用在 predicate,那麼所有在 primary key 中先前的 column 都必須要用上。
- 如果 clustering key 被用來做 range scan predicate,那麼所有在 primary key 中先前的 column 都必須要用上,而且其他的 column 你都不能使用在 predicate
最後兩點比較難以理解,我們用下面的例子當說明,clustering key 是 artifact_id (紅色框框),由於我們用到了它,所以前面所有的 primary key 的 column 都要使用進去 (紫色框框)。

註記: predicate 就是 WHERE 後面那一整包
Conceptual Data & Application Workflow Modeling
介紹完 Cassandra 基本的模型,終於要進入正題,如何設計 Application!
這篇文章的作者一直重申,ER Model 真的是很好的模型,就算不用來開發 Application,也是一個非常好的抽象管理資料的方式。
只是 Cassandra 不適合,Cassandra 就是被創造出來完成某些 Workload 而設計的。所以作者直接給我們一個 Application 的語境,讓我們學著用 Cassandra 設計。
實際案例
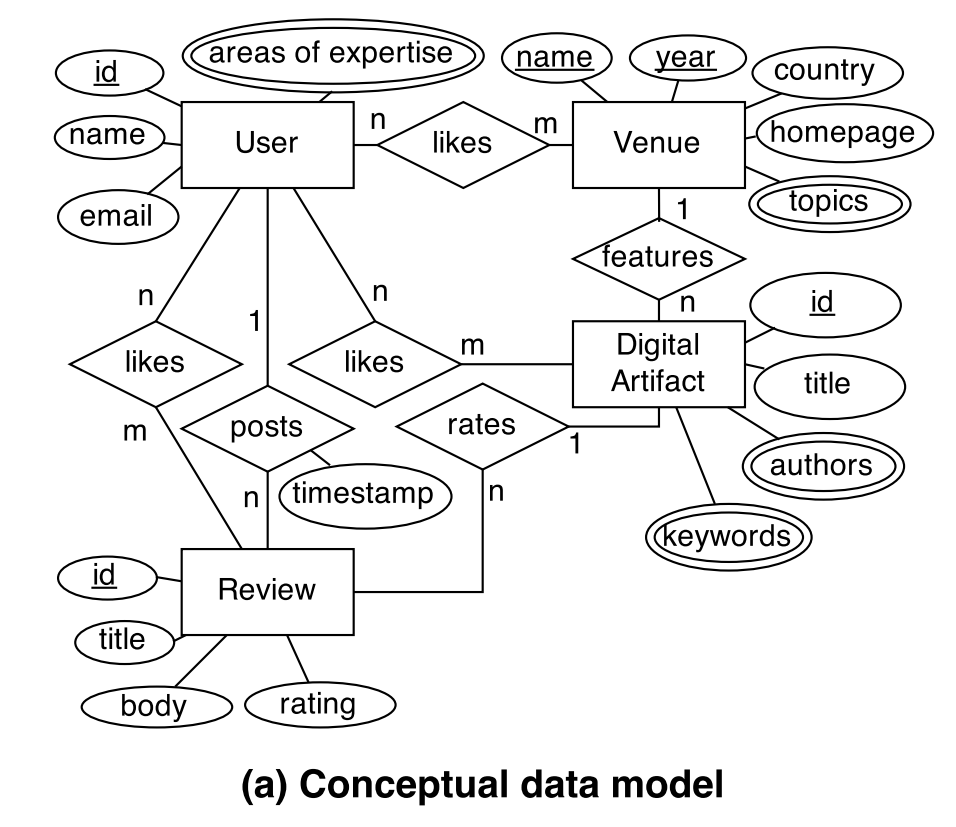
假設我們設計一個數位圖書的服務,保存了不同的 artifacts (有 papers 和 posters) 之類的,會保存在不同的 venues。users 可以留言評論 venues 和 artifacts 像是 reviews、likes、ratings 之類的,如果畫 ER Model 大概會長這樣。
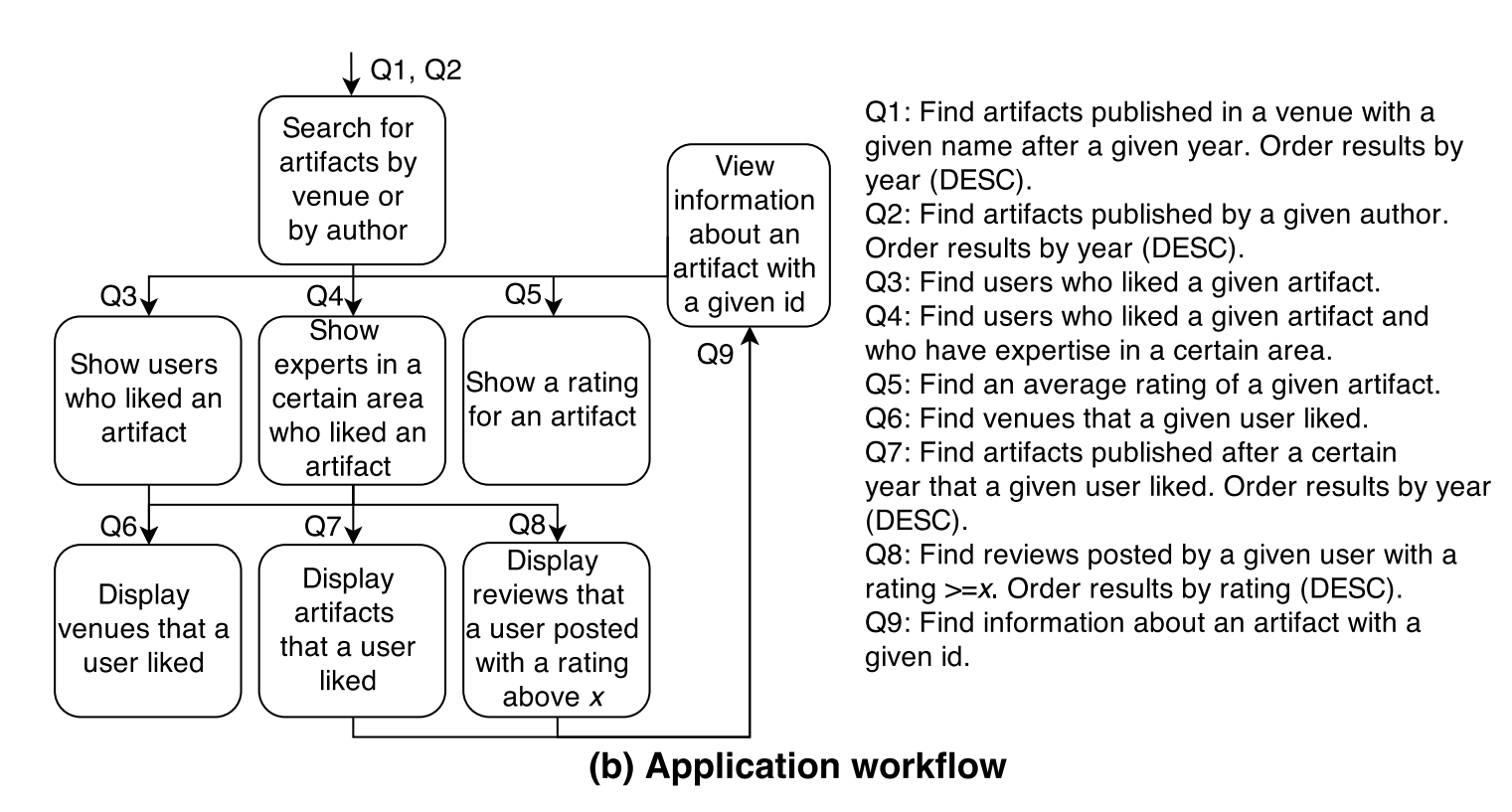
接下來畫出使用者的 workflow 會是像這樣。
Logical Data Modeling
這個部分是 Cassandra 的關鍵,上面列出來的東西 Relation Model 也要做,這個步驟開始就會有完全不同的走向。作者提供了一些技巧給我們參考 (後文統稱 DMP:Data Modeling Principles)
Data Modeling Principles
DMP 1:Know Your Data
這個部分我看了之後覺得和 ER Model 要注意的事情差不多,知道你的 Entity Relation 之間的關係,是一對一、一對多、多對、、多對一,還有一些商業邏輯上的限制,完全是基本功 XD
DMP 2:Know Your Queries
這個步驟就是把使用者 workflow 轉換成真正的 queries,作者統整了三種查詢的方式:
- 查詢一個 partition
- 查詢多個 partition
- 查詢多個 table
顯然,查詢一個 partition是最快的,通常就回傳一個 row,多數 OLTP 的 query 每個使用者都只會接觸到自己那部分的資料,不過也會有需要查詢複數 partition/table 的 query,這種就要特別小心效能上的問題。
DMP 3:Data Nesting
巢狀式資料通常是管理某些相同特性的資料,就以這個例子來說,artifacts_by_venue 這張表把 artifacts 這些 rows “Nesting” 在 venues 這個 partitions,這種例子在 Cassandra 超級常見。
DMP 4:Data Duplication
Cassandra 會把資料複製,來應付各種查詢,舉例來說,上面 Application workflow 的 Q1, Q2,會分別開在不同的 table,擁有各自的 primary key,這是一種以儲存空間換取時間的策略。
Mapping Rules
慢慢的讀者應該可以感覺到,Cassandra 不是 Data-driven 而是 Query-driven,作者提供了五種方式來幫我們完成這些轉換。
MR1:Entities and Relationships
邏輯上你還是是要列 ER Model,這可以避免邏輯上的明顯錯誤,違反了你會做出錯誤又奇怪的 Application。
MR2:Equality Search Attributes
由於 query predicate 有天生的限制 (上面的規則我有講細節),primary key 本身的順序非常重要,尤其是 partition key 和 clustering key,沒設計好,你有些 Equality search query 會根本不能跑。
MR3:Inequality Search Attributes
這點和 MR2 講的是同樣的事情,只是這個是講 Inequality Search 的部分,Cassandra 的 predicate 需要考慮 partition key 和 clustering key。
MR4:Ordering Attributes
如果你需要有 Ordering 的 query,clustering key 就需要特別注意,因為 Cassandra 是照這個 key 排序。
MR5:Key Attributes
這點也是很基本,由於資料本身是被 primary key 管理,如果不小心失去唯一性很可能導致跟著這些 primary key 的資料消失。
MR Example
我們就根據上面的規則來設計看看!
- MR1:artifacts by venue 這張 table 可以對應我們的 ER Model
- MR2:我們用 K 表示 partition key,讓 venue_name 可以被用 Equality Search
- MR3:我們用 C 表示 clustering key,讓我們可以根據年分來排順序
- MR4:我們要考慮一下 query ㄒ要的順序是上升還是下降,在圖中的記號可以用上下箭頭表示
- MR5:最後我們需要 artifact_id 的特性,把它列入 clustering key 之中
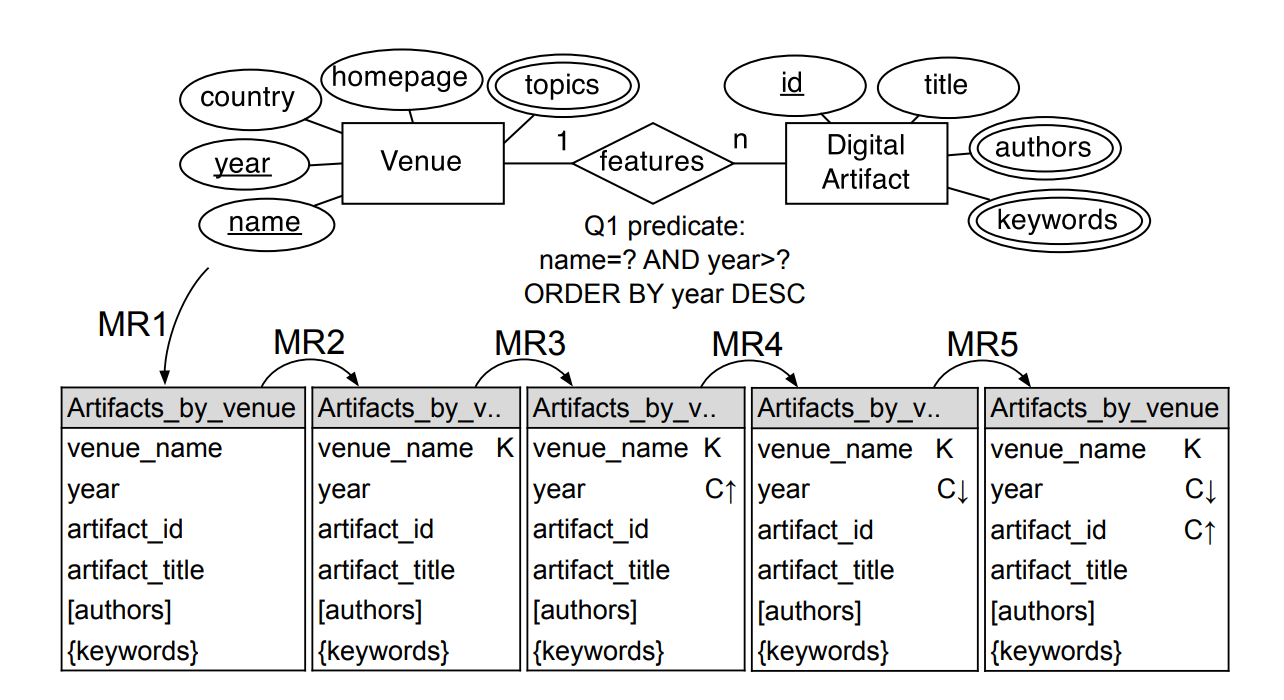
我們在上面的例子可以知道 Cassandra 設計的一些模式,簡而言之,就是以 Query 為中心去發想,上面的例子我們給出 1:N 的模式如何建構。
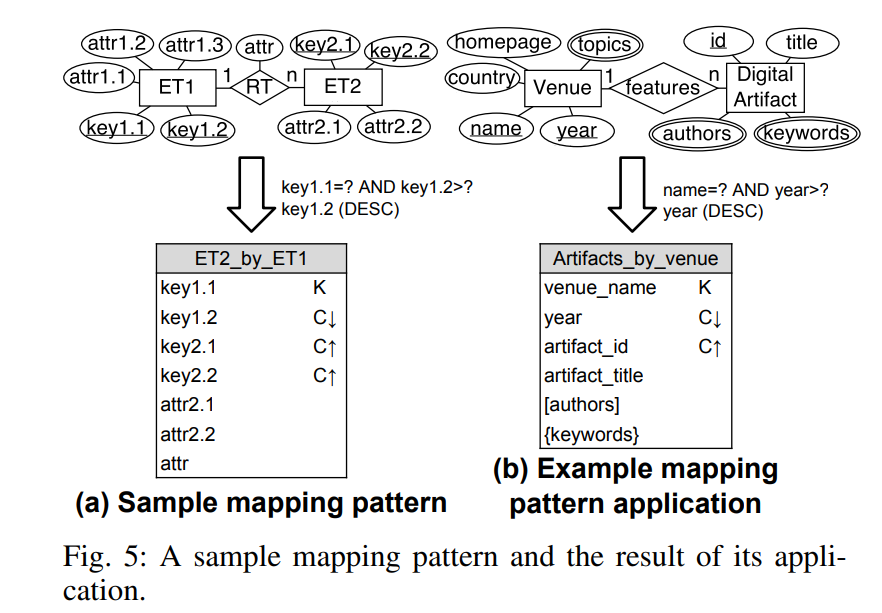
Chebotko Diagrams
我們其實只解釋了一個例子,但是這整個應用程式還有其他 Query 沒解決!作者提出一種方法叫做 Chebotko Diagram 也就是把上面的例子一般化的方式。
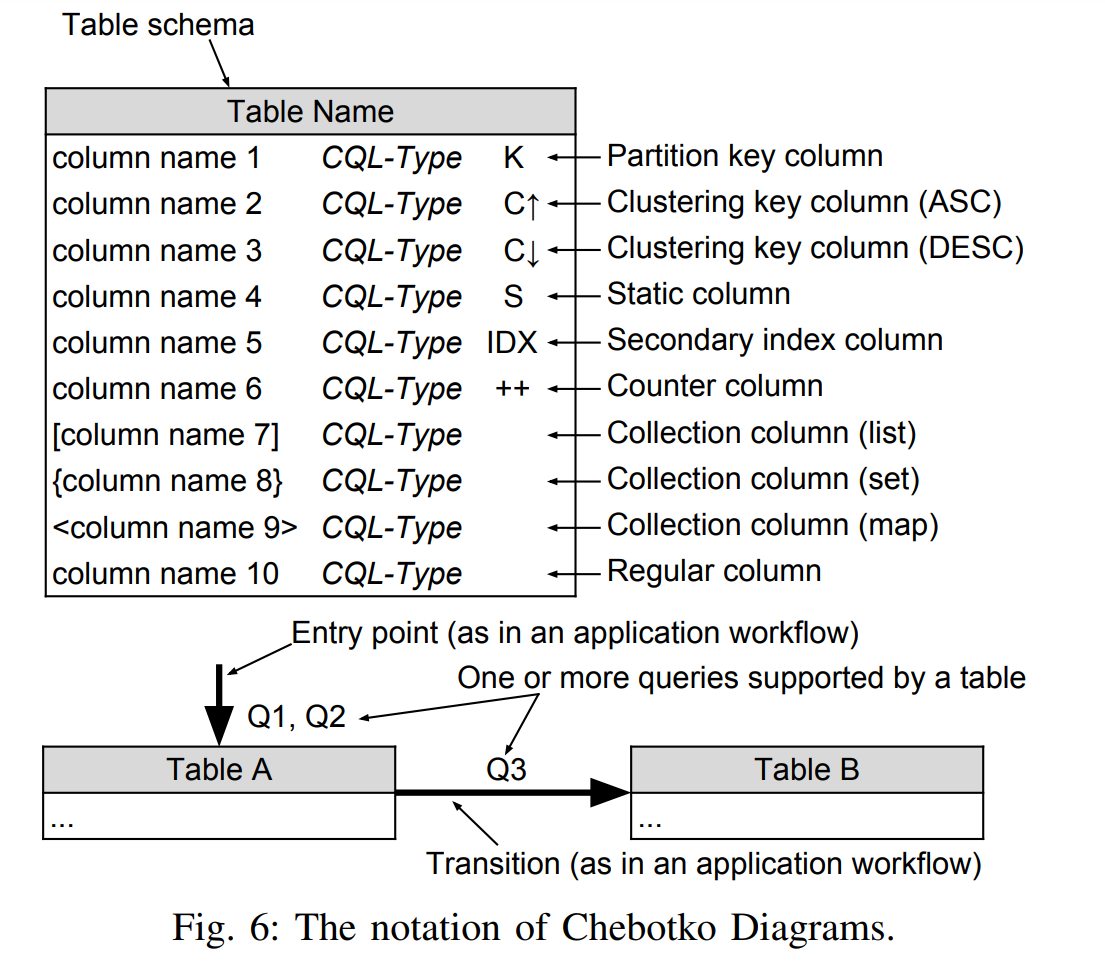
Notation
我們先了解一下 Chebotko Diagrams Notation 的用法,其實蠻好理解的,就不多做解釋。
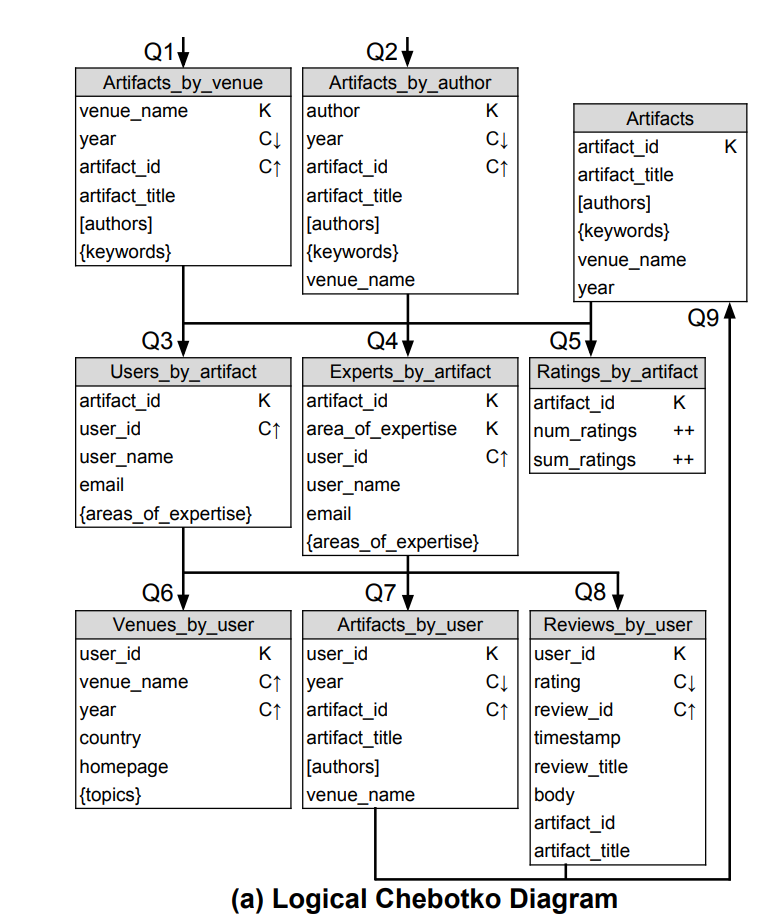
Logical Chebotko Diagram
以下就是上面 Application 的設計,其實概念上真的是簡單粗暴,有幾個 Query 就開幾張表 XD,不過過程中還是需要注意那些規則就是了。
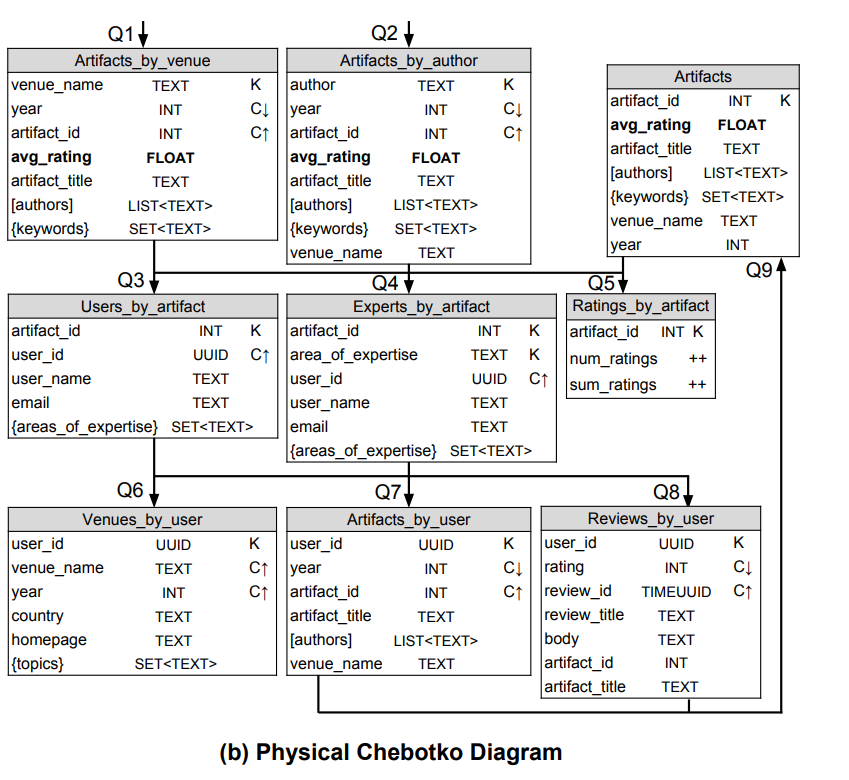
Physical Chebotko Diagram
最後論文有示範一點點優化的技巧,例如:
- Artifacts_by_venue 和 Artifacts_by_author 加入一個 avg_rating 欄位,避免額外的 lookup
- Reviews_by_user 移除了 timestamp 欄位,因為 review_id 可以用 TIMEUUID 表示
注意事項
Physical Data Modeling 也是一個環節,不過在本論文中並沒有提到細節,這部分需要對基礎設施的運作還有實際狀況做討論,已經偏離本論文的主題了 (例如:partition splitting, inverted indexes, data aggregation, concurrent data access),所以我沒有打算去把引用的論文展開來討論,各位讀者有興趣我們有機會再聊聊。
還有 Chebotko Diagram 這個過程可以自動化,也有一些工具 Wayne State University 有開發一套 KDM 的工具,不過網站好像掛掉了,哈哈 ==”。
結論
這篇論文提出的方法論非常的務實,也給出很容易懂的例子,雖然說 Cassandra 在 目前真正最新的 Database 領域已經不算是最新的,但是絕對是經過實戰測試的一套系統,寫這篇論文的工程師本身就是 DataStax (商用版的 Cassandra 分支) 的工程師,自然能夠有很高的參考性,在 IEEE 的引用次數也很高,作為 NoSQL 的入門磚我覺得當之無愧 XD。