<Database 一代代的演化和傳承>

Index
前言
這篇文章會介紹一些 Database 的種類和歷史,主要參考 CMU Database 教授 Andy Pavlo 的一些演講和授課,例如:
- <Andy Pavlo — The official ten-year retrospective of NewSQL databases>
- <History of Databases (CMU Advanced Databases / Spring 2023)>
聲明和導言
這些演講含金量都很高,所以我會選一些內容來說,比如說 Andy 在 History of Databases 這門課從 1960s 開始講 (我都還沒出生ㄟ XD),所以這些內容我會省略。還有可能是曇花一現或是我覺得沒有寫的價值的內容 (不有趣也沒有成功的例子),如果真的有興趣可以自己去看影片。
主要的內容我會選擇是從 Ted Codd 在 1970s 提出最經典的 Relational Model 開始寫。
1970s:Begin
由一位數學家 Ted Codd 的一篇 Paper <A relational model of data for large shared data banks> 開始當代 Database 的基礎,也就是大家熟知的 ER Model 起源就是這篇 Paper。
雖然這篇 Papar 大家都覺得很精妙,但是畢竟沒有實作出真正的軟體,所以就有一些人常是基於這篇 Paper 來實作系統例如:
1980s:Relational & Object-Oriented Databases

顯然以結果論來說,Relational Model 獲得了很大的成功,例如:IBM / Oracle 就是在這時候起飛的 (這時候 Oracle 獲得了市場的青睞)。
Stonebraker 回去 Berkeley 開啟了一個新的專案也就是大家熟知的 Postgres (字面上的意思就是 Post + INGRES),主要概念就是 Object 和 Relational 的結合。
舉個例子來說:如果你要取用 Student 的 Phone Number,要做一些 JOIN 才能得到結果。
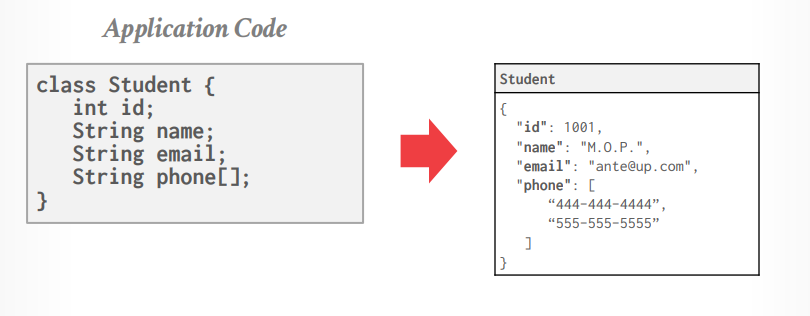
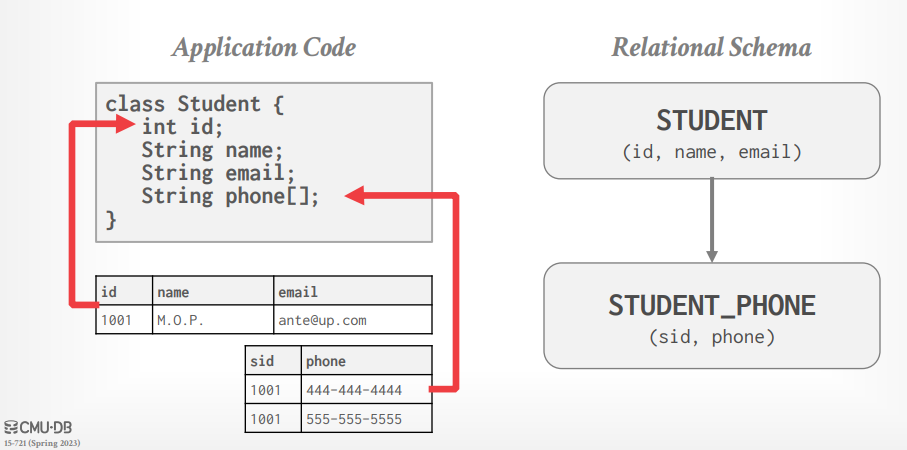 那為甚麼我們不直接當成一個 Object 來存取?(這就是 Object-Oriented 的概念)
那為甚麼我們不直接當成一個 Object 來存取?(這就是 Object-Oriented 的概念)
1990s:無聊的年代
Andy 講明了這期間沒有甚麼技術和觀念的新發現,基本上就是延續 1980s 的動力,例如:
- Microsoft fork Sybase 然後打造 SQL Server
- MySQL 開始撰寫,目的是取代 mSQL
- Postgres 開始支援 SQL
- SQLite 約莫在 2000 開始實作

2000s:Internet Boom!
早期:老系統還撐著
在 2000 年早期,網路開始蓬勃發展,幾乎所有你想像的到的業務都開始遷移到網路上,這格時候的 Database 還被許多企業大頭獨佔,例如 Oracle、MS SQL、IBM DB2,大家熟知的 Open-source Database,例如:Postgres、MySQL,都還非常不成熟,這時的技術還只能單純購買更好的硬體把效能頂上去。
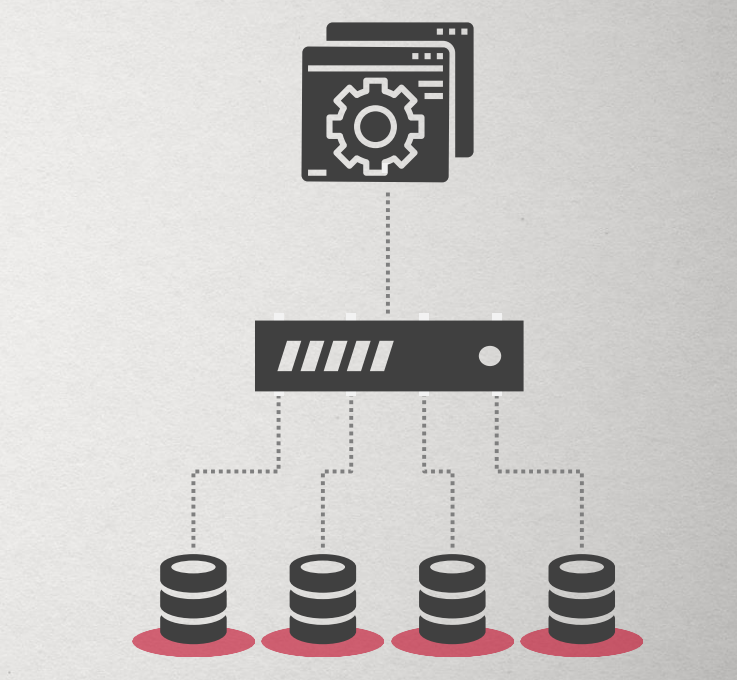
中期:Middle-ware
到了 2000s 的中期,開始出現 Sharding Middleware,有人設計出一些 Middleware 讓許多 Single-Node 的系統可以經由 Middleware 的 Route 互相合作。
這個時候的軟體開發大多是使用這個方法,包含大家所熟知的 Google、Facebook,就算到了今天,Facebook 的部分系統還是使用著個方法,例如:在一堆 MySQL 上面使用 Middleware。
這種方法雖然可以 Scale,但是缺點就是工程師多半把時間花在開發管理 Middleware 而不是開發應用程式 XD。
晚期:NoSQL
到了 2000s 後期,開始出現所謂的 NoSQL,大家發現在線上運行的業務幾乎要 24/7 完全不能停止服務 (a.k.a High-Availability),而且還要能夠 Scale。
在此之上犧牲了 SQL 所擁有的嚴格標準,像是 ACID Transaction 的保證、Schema,最知名的就是 Google BigTable 和 AWS 的 Dynamo (這邊指的是當時的 Paper,現今的 Dynamo 已經可以支援某些 Transaction)。
- Bigtable: A Distributed Storage System for Structured Data
- Dynamo: Amazon’s highly available key-value store
當這兩篇 Paper 發表之後,許多 NoSQL 公司都如雨後春筍,在 Key/Value 領域有 Redis、AEROSPIKE、Dynamo;Wide-Column 領域有 Cassandra、HBase、BigTable;Documents 領域有 Mongo、CouchBase ……。

這些的概念都因應上面講的情境,在網頁開發的系統上,犧牲了 Transaction 和 Join 等 SQL 的特性,變成了新的資料模型和新的 Transaction 保證 (最終一致性)。
Data Warehouse
Data Warehouse 的概念也在這個時期萌芽,也就是 OLAP,許多人發現對於大量資料的分析其實是有市場的,就開始用 columnar data storage model,OLTP 為了支援 Transaction 通常都是 row model。
以下是一些例子:
- VERTICA:Stonebraker 的大作,主要客戶是 HP
- Greenplum:shard Postgres 製作成的,被 Dell EMC 收購
- PARACCEL:有一部分的 Licences 賣給 AWS 掉變成 RedShift,Wow!好酷,database 冷知識!
- NETEZZA:加裝 FPGA 的特化版本 Postgres,最後被 IBM 買走
- DATAllego:用 shard 的 Ingres,被 Microsoft 買下來,但是發現根本不能用所以就被丟到垃圾桶了 QQ (這不是商業機密,至少 Andy 是這個說的 XD)

2010s:Cloud Systems
由於 Cloud 的興起,AWS 之類的廠商開始提供 VM,幫你運作這些細節,你不太需要花力氣去維護,也就是 DBaaS (database-as-a-service)。

2010s:Graph Database
這種系統把 Graph 當作主要模型,提供了一系列的 API,優點就是可以很好的支援 graph-centric Query,這也是它唯一比其他 database 好的優點。
但是 SQL:2023 也納入了 Graph 的模型,也能做到同樣的事情,而且最近的論文顯示,Relational DBMS 比當今最強的 Graph Database 效能要好 x10,所以 Andy 對 Graph Database 抱持著悲觀的態度。

2010s:Time-Series Database
這是一種比較小眾的領域,多半是用來蒐集 time-series/event 之類的,多半是用來收集一些應用程式的監控資料,應用的領域很特定,多半 index 都會是基於時間做優化。

2010s:NewSQL
Google Spanner
接著時間移到 2012 年,Google 的頂尖科學家 Jeff Dean 發表了 Spanner,這個系統算是 NewSQL 的先驅,能夠同時具有 NoSQL 的 Scale 特性和 SQL 一樣的 ACID Transaction 保證。其中論文有一段提到……
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
對於開發軟體的人來說,與其用沒有 Transaction 保證的系統修修補補,直接使用一個有 Transaction 保證的系統會更好
Michael Stonebraker (在 Database 有極大貢獻的科學家兼工程師,得過圖靈獎、Postgres 的發起人) 也給出了 NewSQL 的定義……
- SQL as Primary Interface
- ACID for Transaction
- High Per-node Performance
- Non-Locking Concurrency Control
- Share-Nothing Architecture
以上前四點 CMU Database 教授 Andy Pavlo 基本上都同意,不過最後一點要特別提一下,Michael Stonebraker 當時在做一個 VoltDB 的 Database Project,而 VoltDB 本身就是 Share-Nothing Architecture,所以想當然會把這個列為標準,多多少少算是本位主義 XD。
寫到這裡,如果把上面提到的系統畫在表上,會向是下圖所呈現。

NewSQL 黃金年代
就如同 NoSQL 的論文發表時一樣,NewSQL 也如同雨後春筍一樣,NuoDB、VoltDB、memSQL、FoundationDB、SAP HANA、Google Spanner……,也由於是新的系統架構,也沒有舊有的包袱大多都採用 Share-Nothing 的架構。
同時間,除了開發新的 Database,也有人選擇把 NewSQL 的標準拿來做 Middleware,比起 2000s 的方式,這些實作有更明確的標準,知名的系統有 ScaleBase、ScaleArc、CitusData、Continuent……,通常都會支援 MySQL 或是 Postgres 的 Interface Protocol。
哪裡出問題了?
讀到這裡,大家應該可以認知到,一定有些事情做錯了,如果真的 NewSQL 真的這麼厲害又有價值,那麼為甚麼現在上面所提到的公司沒有統治整個 OLTP Database 的世界?
實際上也是,舉例來說:
- Google Spanner 本來就不是拿來賣的,那是給 Google 內部使用
- SAP 本業是企業資源管理軟體,也不是賣 Database 的;ScaleBase 被買走也消失了
- FoundationDB 被 Apple 買走,等我們見到的時候已經變成 Key/Value Open-source 的專案,現在主要是 Snowflake 的大客戶
- memSQL 現在改名成 SingleStore 專注於 Analyze 的市場;其他不是倒了就是轉換跑道去某些特定領域
Andy Pavlo 給出的結論是,NewSQL 是個很難賣的東西,OLTP 可以說是公司的命脈,轉換的風險非常大,只要 OLTP 停機幾天,公司就沒有收入,這也可以解釋 IBM IMS 這種年紀很大的系統還是有很多客戶。
再來,現在 Open-Source 的 SQL,已經做的超級棒,還不用錢,對於新創公司,根本沒什麼資料,也不會選擇 NewSQL。例如:Postgres、MySQL,
就算有些公司有接納 NewSQL 的想法,現在的 Cloud Service 也幫忙處理了很多的棘手的維運問題,省時又便利,NewSQL 在這個市場也沒有競爭性。
Open-source 方面也缺少了這方面的專案,對於想要嘗試看看的開發者也沒有門路。上述的種種原因,可以很好的解釋 NewSQL 所遇到的商業難題。
Andy Pavlo 的總結
對於學術上,NewSQL 的概念可以說是非常重要的一步;但是業界的 NewSQL 甚至可以說是錯誤的策略
Now:Distributed SQL 大風大浪後的生還者
經過這 10 年的演化,NewSQL 這個詞可以說是已經死了,但是卻有一批人在 NewSQL 的保護傘活了下來,也就是 Distributed SQL。Distributed SQL 這個詞比起 NewSQL 更體現了要 Address 的問題,也就是在分散式系統的環境下的 SQL Database。
雖然核心概念和 NewSQL 差不了多少,不過至少他們拿到很多 Funding,像是 CockroachDB、TiDB、Planetscale、YugaByte,這些 Project 可以說是我們這種研究密集型資料系統人的聖經。

同樣的 NoSQL 開始學習很多 Distributed SQL 的概念,像是 Cassandra、Mongo、Couchbase,也開始支援 Join、Transaction,未來的界線會更加的模糊。

結語
讀這些文章和聽這些演講的時候,我完全不會覺得像在工作,反而像是看連續劇一樣,尤其當自己有在寫 code 有在學 database,就對其中的故事著迷,世界是很大的,彼此之間的關聯又錯綜複雜,不過這不就是真實世界的樣貌嗎?