<Discord 如何 Full-text Index 數十億的訊息>

Index
前言
這篇部落格會翻譯和參考 <How discord indexes billions of messages> 這篇文章的內容做整理和翻譯。
這篇算是 <Discord 如何處理數十億的訊息> 的下集,當有了最核心的訊息讀寫系統。下一個很重要的 feature 就是 Full-text Search。
舉例來說,User 突然想到以前和同伴討論的某個議題,不可能慢慢滑去找,而是要用像是 Search Engine 這樣的功能,這篇文章就是在介紹 Discord 如何做到這種功能。
需求
一開始作者先把需求給羅列清楚:
對於 Discord 來說,主要的服務還是語音和訊息,全文搜尋的功能算是附加的功能,就意味著我們不應該在這個功能花過多得費用 (至少要比語音和訊息的 Infra 還少!)
當然加一個新功能需要能讓使用者覺得很順利很好用,這是基本。
由於我們的團隊還沒有 DevOps 團隊,我們希望可以 Self-healing
畢竟 Discord 是超大流量的公司,我們當然希望能夠單純增加 Node 就能增加 throughput。
由於並不是每一個 User 都會使用 Index,只要 User 不使用我們就不該做這件事情,另外如果 Index 失敗了,我們要有辦法重新 Index。
解決方案
當我們仔細思量上面統整的需求,我們總和出了兩個主要問題。
Question 1:我該用外部的 SaaS 去解決這個問題嗎?
這題的答案絕對是不行!在 Discord 這個 Scale 我們參考了一些外部的廠商,會發現預算一定會爆炸…。再來,我們對於隱私有很大的考量,如果把資料運出去我們的 Data Center 誰知道那些廠商會不會保護好我們的資料?
Question 2:有 Open-source 的方案可以用嗎?
有的!我們內部討論之後,發現有 Elasticsearch 和 Solr 可以選擇,我們發現 Elasticsearch 有以下優勢。
- Solr 本身需要搭配 ZooKeeper,我們內部是用 etcd,我們不想花精力去維護額外的基礎設施。還有 Elasticsearch’s Zen 本身有內建的服務發現,這方面比 Solr 有更多優勢。
- Elasticsearch 支援 automatic shard rebalancing (分片自動平衡),當我們增加新的 Node 可以滿足 Linearly Scalable 這個需求。
- Elasticsearch 本身有內建自己的查詢語言 (structured query DSL),不需要像 Solr 寫第三方的查詢字串。
- 我們的工程師對 Elasticsearch 比較有經驗… XD
註記1:這篇文章是 2017 年寫的,那時的 Full-text 基礎設施的確不多,但是現在已經有很新的解決方案,例如:Meilisearch、Zinc、Typesense,甚至如果你流量沒有像 Discord 那摩暴力,Postgres 本身其實也有 Full-text Search。
註記2:automatic shard rebalancing,這個詞的意思是指當資料量過大時必須要分散在不同的 Node這是 shard 的意思。當增加新的 Node 裡面還沒有資料較需要把部分資料做搬移,就是 rebalancing。而 automatic 就是照整個過程是系統自動完成的 (Actually 這個 feature 是很難做的如果又要 online 做)。
我們該”全面”相信 Elasticsearch 嗎?
經由我們的分析 Elasticsearch 雖然所有我們想要的 feature 都有提供,但是我們並沒有管理大型 Elasticsearch Cluster 的經驗,我們目前只有拿來做 log 的用途,All-in實在是會怕。
所以我們選擇一個折衷的方案,我們在 Application Layer 做 sharding 和 routing,我們維護很多小小的 Elasticsearch Cluster,就算故障了,也只有那個 shard 的 user 會被影響。就算更誇張一點,整個小 Cluster 都死了,下次再 lazily re-index 就好。
元件的細節
高層次分析
Elasticsearch 語意上是以 bulk 的方式 indexed,也就意味著我們沒辦法 Real-time 的更新。我們採取一個 Queue 的方式,再用 worker batch 寫入。至於這種延遲之所以可以忍受,是因為多半用到 Full-text 的人都是搜尋歷史紀錄,沒有必要做到 Real-time,以下我們開始介紹有什麼元件。
Insert 元件
- Message Queue:可以先把 Messages buffer 起來。
- Index Workers:專門把 Messages 從 Message Queue 送入 Elasticsearch。
- Historical Index Workers:負責把 Messages 歷史紀錄 送入 Elasticsearch。
Shard Manage 元件
由於剛剛我上面有說 Discord 自行管理很多 Elastic Search Cluster,我們把 (Elasticsearch cluster, Discord server Index) 作為 shard 的管理,就是 Application 需要把 cluster + index 轉換成 shard,又可以拆分成以下兩層:
我們把這種 Mapping 放在 Cassandra (我們的主要資料庫)
如果每次 Discord server 要去找自己的 Full-text Index shard,都要進去 Cassandra 查會很浪費時間,所以用 Redis Cache 起來,並且用 mget 來得到結果。
當 Discord server 第一次請求 Index 時我們需要決定要用哪一個 Shard,由於邏輯是寫在 Application 我們用 Redis 做了一個 load aware shard allocator。
我們用 Redis 的 sorted set 來實作,我們幫每一個 Shard 排序一個分數,分數意味 load,得分最低的就會是下次被分配的 shard。每一次分配都會更新分數,當 shard 的分數變高,未來被分配到的機率就會越低。
雖然上面的設計已經很完整了,但是要能夠動起來需要讓服務被發現,我們需要協調 Application 和 Infra。
- etcd:
這個工作就由 etcd 負責 service discovery,etcd 可以管理的很好,我們不用去手刻Elasticsearch topologies 管理層。
最外層還是要包成 API,主要只是驗證有沒有權限去察看某些 Index
註記:etcd 可是 kubernetes 的核心,基本上屬於超級強的實戰系統!Respect!
Indexing & Mapping the Data
在最抽象的層次,我們其實就只是一堆 shards 而這些 shards 是 Lucene index (如果去查一下 wiki,Elasticsearch 就是用 Apache Lucene Java Library 實作的)。如果你想要你可以用 routing key 來分配 sharding 的位置。
細節上我們還可以設計 replica,複製多份同樣的 shard 一來可以增加 HA 的特性,二來可以衝高特定熱門 shard 的 throughput。
雖然我們已經自己在 Application Level 手刻 Sharding,我們壓根沒在用 Elasticsearch shard,但是 replication 和 balancing 在 Elasticsearch 小 cluster 還是蠻好用的,以下就介紹一下我們怎麼設定。
- index 只能有屬於一個 shard
- index 應該 replicated 到另外一個 node,primary 掛掉了服務還能繼續
- index 60 秒刷新一次,為什麼不是 Real-time 上面有解釋
- index 只有一種 document type:message
最後一點特別解釋,我們不存原始的資料,這種意義不大,我們順便把 metadata 啥的全都塞進去,這樣就可以搜到超多東西,以下是我們 index 模板的範例。可以看到,縮有東西都塞…塞進去了,簡單暴力!
{
'template': 'm-*',
'settings': {
'number_of_shards': 1,
'number_of_replicas': 1,
'index.refresh_interval': '3600s'
},
'mappings': {
'message': {
'_source': {
'includes': [
'id',
'channel_id',
'guild_id'
]
},
'properties': {
# This is the message_id, we index by this to allow for greater than/less than queries, so we can search
# before, on, and after.
'id': {
'type': 'long'
},
# Lets us search with the "in:#channel-name" modifier.
'channel_id': {
'type': 'long'
},
# Lets us scope a search to a given server.
'guild_id': {
'type': 'long'
},
# Lets us search "from:Someone#0001"
'author_id': {
'type': 'long'
},
# Is the author a user, bot or webhook? Not yet exposed in client.
'author_type': {
'type': 'byte'
},
# Regular chat message, system message...
'type': {
'type': 'short'
},
# Who was mentioned, "mentions:Person#1234"
'mentions': {
'type': 'long'
},
# Was "@everyone" mentioned (only true if the author had permission to @everyone at the time).
# This accounts for the case where "@everyone" could be in a message, but it had no effect,
# because the user doesn't have permissions to ping everyone.
'mention_everyone': {
'type': 'boolean'
},
# Array of [message content, embed title, embed author, embed description, ...]
# for full-text search.
'content': {
'type': 'text',
'fields': {
'lang_analyzed': {
'type': 'text',
'analyzer': 'english'
}
}
},
# An array of shorts, specifying what type of media the message has. "has:link|image|video|embed|file".
'has': {
'type': 'short'
},
# An array of normalized hostnames in the message, traverse up to the domain. Not yet exposed in client.
# "http://foo.bar.com" gets turned into ["foo.bar.com", "bar.com"]
'link_hostnames': {
'type': 'keyword'
},
# Embed providers as returned by oembed, i.e. "Youtube". Not yet exposed in client.
'embed_providers': {
'type': 'keyword'
},
# Embed type as returned by oembed. Not yet exposed in client.
'embed_types': {
'type': 'keyword'
},
# File extensions of attachments, i.e. "fileType:mp3"
'attachment_extensions': {
'type': 'keyword'
},
# The filenames of the attachments. Not yet exposed in client.
'attachment_filenames': {
'type': 'text',
'analyzer': 'simple'
}
}
}
}
}
作者有提到他們並沒有直接把 messages 存到 Elasticsearch,而是當 inverted index 用,所以當你搜尋某些關鍵字,Elasticsearch 不能直接給你資料,而是給你 message, channel 和 server ID,你還是需要拿這些東西去 Cassandra 取回原始資料。
實際上 Coding 的實作
我們決定不用微服務,而是寫一個 library 把 Query 的邏輯包進去。我們唯一需要的額外服務就是 index worker,也就是上面那個我們把 routing + querying 寫成 library 的使用者,實際的 API 例子就是下面的 code。
results = router.search(SearchQuery(
guild_id=112233445566778899,
content="hey jake",
channel_ids=[166705234528174080, 228695132507996160]
))
results_with_context = gather_results(results, context_size=2)
Queueing 一則訊息用來 indexed/deleted
# When a message was created or updated:
broker.enqueue_message(message)
# When a message was deleted:
broker.enqueue_delete(message)
Bulk indexing 的 code (被 worker 執行)
def gather_messages(num_to_gather=100):
messages = []
while len(messages) < num_to_gather:
messages.append(broker.pop_message())
return messages
while True:
messages = gather_messages()
router.index_messages(messages)
接著對於 historical messages,會是以 job 為單位一個一個序列 index,實際上會維護一個 cursor 然後以 500 則 messages 為單位進行處理。處理完成之後會回傳下一個 cursor 直到所有 historical messages 都被 index。
為了加快大型 server (這裡我想語意指的是我們用的 Discord server,不是他們的 Application Server),historical indexing 有兩個階段:
執行的 code 大概長的像以下:
@task()
def job_task(current_job)
# .process returns the next job to execute, or None if there are no more jobs to execute.
next_job = current_job.process(router)
if next_job:
job_task.delay(next_job, priority=LOW if next_job.deep else NORMAL)
initial_job = HistoricalIndexJob(guild_id=112233445566778899)
job_task.delay(initial_job)
實際在 Production 的過程
初始化實驗
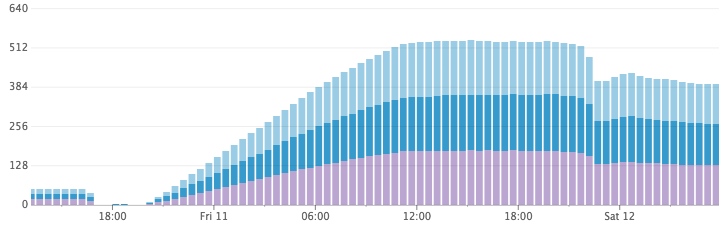
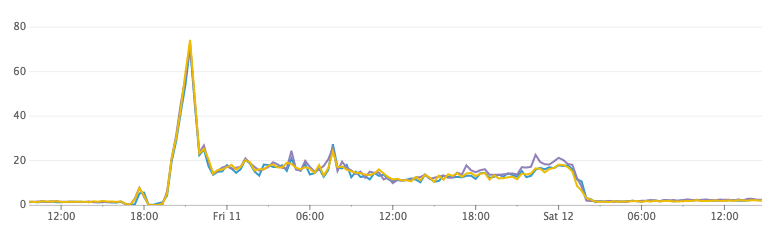
最精采的實戰部分來拉,我們根據以上的設計,一開始先開 single Elasticsearch cluster (只有 3 個 Nodes),然後部屬 index workers,然後排程最大的 1000 個使用者的 servers 來 index,這個階段是做實驗,我們會仔細研究 metrics,我們注意到兩件事情:
跑一段時間之後,Disk 快沒空間了,我們取消了 index 的過程,事情真的怪怪的……
結果第二天上班回來,我們發現神奇的事情 Disk 縮小了!!我們開始懷疑是不是 Elasticsearch 把我們的資料丟了,但是打一下 API 不僅正確而且超級快!為啥???????
Disk 成長量
CPU 使用率
研究的精神
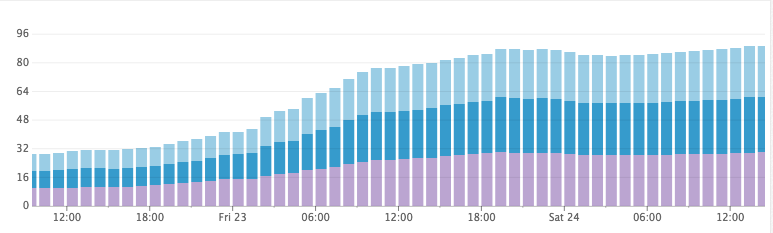
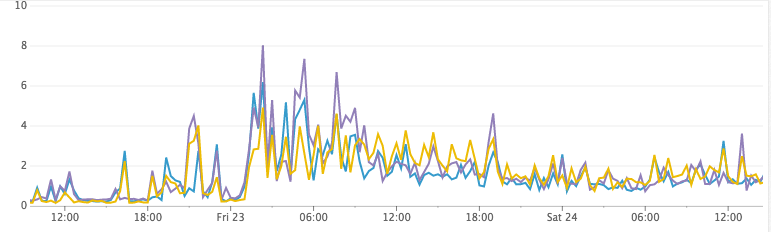
在研究了一下之後,我們提出一個 假說:預設情況 Elasticsearch 會以每 1 秒為單位,然後刷新 index,這可以提供 “near real-time” 搜尋的能力,而且同時會把數千個 index 放到 buffer 中 Lucene segment。晚上 Elasticsearch 就會偷偷合併 segment,所以 Disk 就會縮減容量。
要測試這個假說也很簡單,就直接把所有先前的 index 丟掉,然後把刷新的間隔調超大,CPU 瞬間歸零,Disk 也沒有爆炸性增長,太神拉!
Disk 成長量 (調整刷新參數過後)
CPU 使用率 (調整刷新參數過後)
更新的煩惱
顯然,Elasticsearch 內建的 near real-time index 我們沒有要用。可能一個 server 好幾個小時都沒有一次查詢,我們必須在 Application Layer 設計一層更新策略。我們用 Redis Expiring hashmap 做到這點,由於本身 server 和 Elasticsearch 一起被 shard,我們可以很方便的持續追蹤更新狀態。
實踐上也很簡單,Redis key 就是 prefix + shard_key 的 Hashmap 管理 guild_id ⇒ sentinel value,由此決定要不要刷新 index,以下是完整的 lifecycle:
Indexing lifecycle
- 從 Queue 取 N 則訊息
- 用 guild_id 找到需要 route 的 shard
- 執行 bulk insert
- 更新 Redis mappings 標記成 dirty,一個小時後就會過期
Search lifecycle
- 根據 guild_id 找到自己需要的搜尋的 shard
- 檢查 Redis mapping,是否要查的 guild_id 是 dirty
- 如果是 dirty 刷新 Elasticsearch Index,然後標記成 clean
- 執行 query 本身
你可能已經發現,我們設計流程已經有包含了刷新邏輯,不過我們還是有設計每個小時的自動刷新 index。也就是說就算 Redis 掛了,最多一個小時之後,系統就會自動修復。
The Future
目前為止,我們運行了 14 nodes, 2 clusters 用的機器是 n1-standard-8 instance (GCP),都帶有 1TB 的 SSD。總共的 document 有 26 billion。增加的速度大約每秒 30,000 messages,Elasticsearch 大約只花了 5–15% CPU。
我們的 library 可以讓我們輕鬆的增加 nodes 都不是問題,shard 真是偉大的發明阿!
至於甚麼時候要擴張我們的 cluster,我們參考四個主要指標:
- heap_free:JVM 如果發生了 Stop-The-World GC,那就要要考慮加 node 了。
- disk_free:沒有 Disk 空間當然就要加 node,不過單純 Disk 不夠用 GCP 可以輕鬆的換機器大小,GCP 真香。
- cpu_usage:CPU usage 在尖峰時刻過高
- io_wait:如果 I/O 操作過於緩慢的話
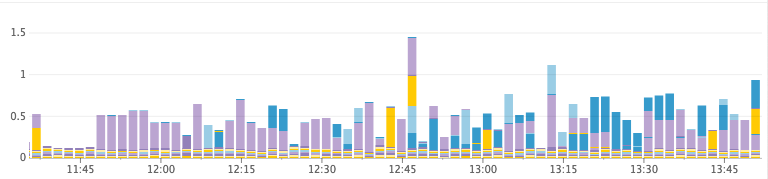
Example:Unhealthy Cluster (ran out of heap)
Heap Free (MiB)
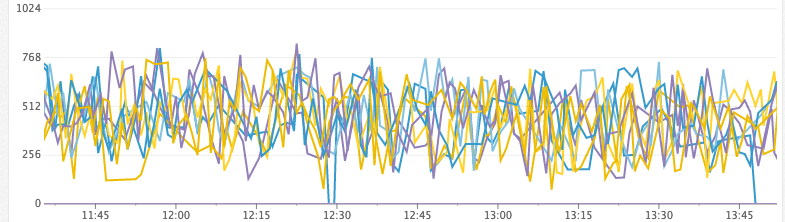
Time Spent GC/s
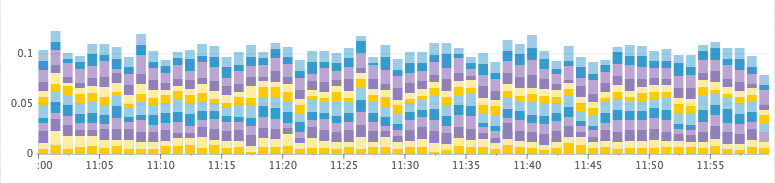
Example:Healthy Cluster
Heap Free (GiB)
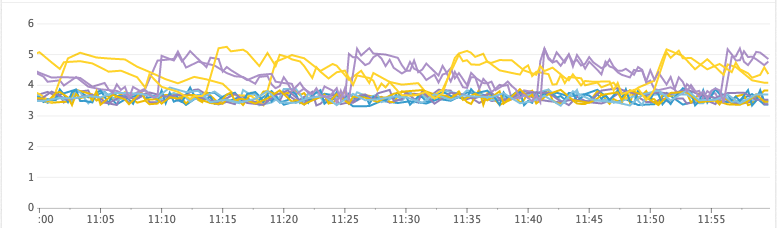
Time Spent GC/s
結論
截至目前為止,我們的系統都表現的超棒,身為使用者的我也這麼覺得 XD。Elasticsearch 從 0 到 26 billion documents 包含 16,000 indices,都沒有甚麼問題。在未來或許我們會考慮寫在 clusters 之間 migrate indices,以防出現那種超級多訊息的 Discord server,不過作者說目前為止好像沒有必要拉 XD,我們的 sharding 做得很好。
感想
這部分我就寫寫我自己的感想吧!在研究這篇文章時我原本預期會沒啥內容,阿不就 Elasticsearch 開下去就好了 XD 不過比我想的精彩許多,由於 Discord 已經是超大的 SaaS,完全信任第三方的 Infra 本身就蘊含了不確定性危機,用自己可以控制的 code 去使用第三方軟體開發服務是一個折衷的策略。
回到以前在和周志遠老師學分散式系統的時候,第一章說分散式系統是靠溝通達成的,這篇文章算是給我一個很大的實際案例解說,在文章裡面你沒有看到一堆超硬的 Algorithm,而是如何精妙的打造產品,用的工具也就是 Queue 和 Worker 而已,看完覺得感動 >///<。