<gravity-router: On-demand Look-aside Distributed Cache>

Index
簡介
這篇文章會用 gravity-router 這個專案解釋 On-demand Look-aside Distributed Cache 這個概念,如果對 cache 論文有些經驗的讀者,這篇文章其實就是實作 Scaling Memcache at Facebook。
Cache 策略
什麼是 On-demand Look-aside Cache?
On-demand Look-aside Cache 是一種 Cache Policy,被廣泛應用在各種大型公司的網站,第一篇真正比較有系統化的論文就是由 Facebook 在 NSDI-13 期刊所發表,就算到了現在 2023 年,這個方法還是不會過時。
例如: Pinterest 在其工程部落格 Scaling Cache Infrastructure at Pinterest 也採用此方法,Twitter 有 153 個微服務 cluster,也是採用這種方法管理超過 80TB 的 cache,詳細可以參考 這篇論文 A Large-scale Analysis of Hundreds of In-memory Key-value Cache Clusters at Twitter。希望這裡列舉的文獻已經夠說服各位讀者這個方法所具有的廣泛應用性。
那就進入實際上 Look-aside Cache 的機制怎麼運作吧!
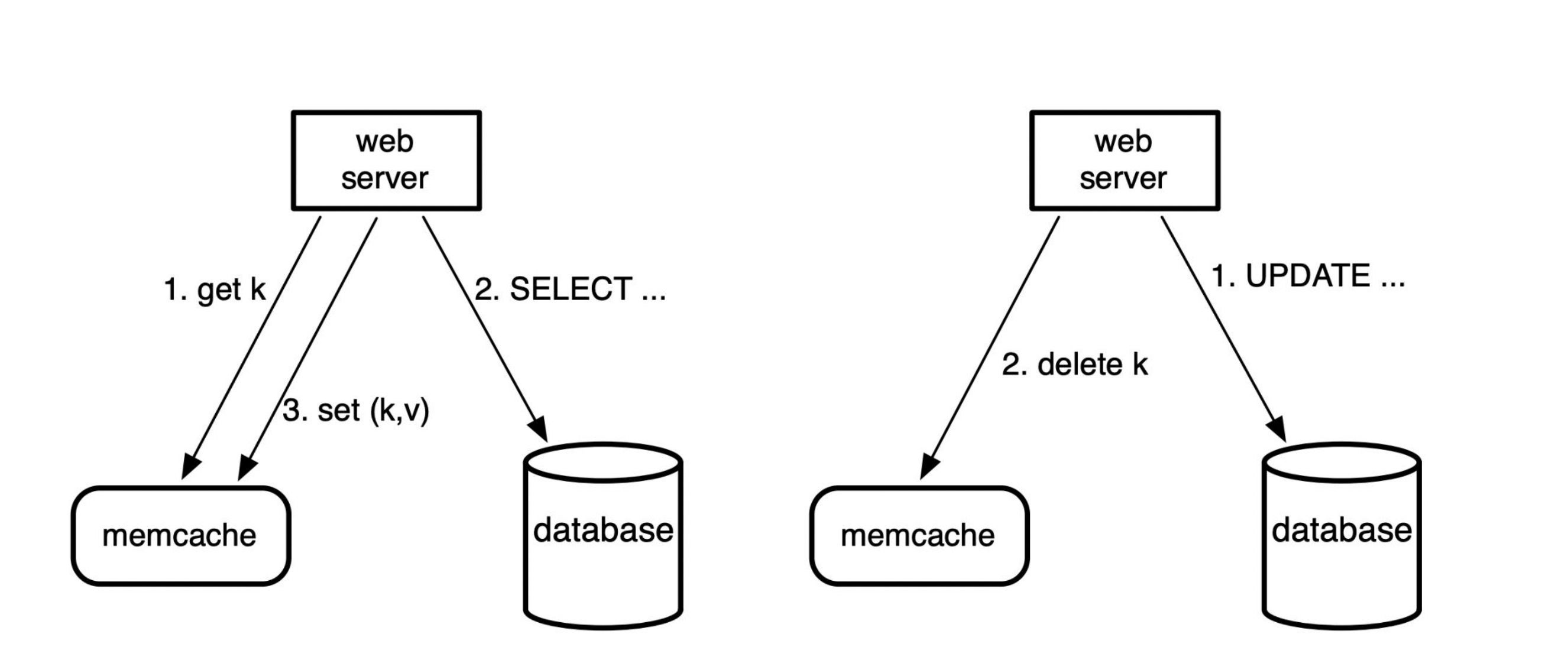
其實講起來這種 Policy 非常的好懂,以下是讀寫的邏輯
- Read: 先去 cache 找資料
- 如果 Hit 就回傳
- 如果 Miss 就先去 Database 爬資料,然後存回去 cache
- Write: 先寫入 Database,再刪除 cache 的資料
Read 應該很直觀,比較有趣的是 Write,會發現 Write 並不是把更新的資料寫回去 cache,而是直接刪除!把回填 cache 的工作交給讀的 Query 去回填,這一定程度避免了 cache 和 Database 的一致性問題。
Cluster
雖然上面講解的圖例只有一個 cache,但實際上通常都會是一個 cluster,對於大量資料水平擴展才有幫助。所以會是像下圖的架構,Application Server 會經由一層 Proxy 把相對應的請求轉發到對應的 cache instance。
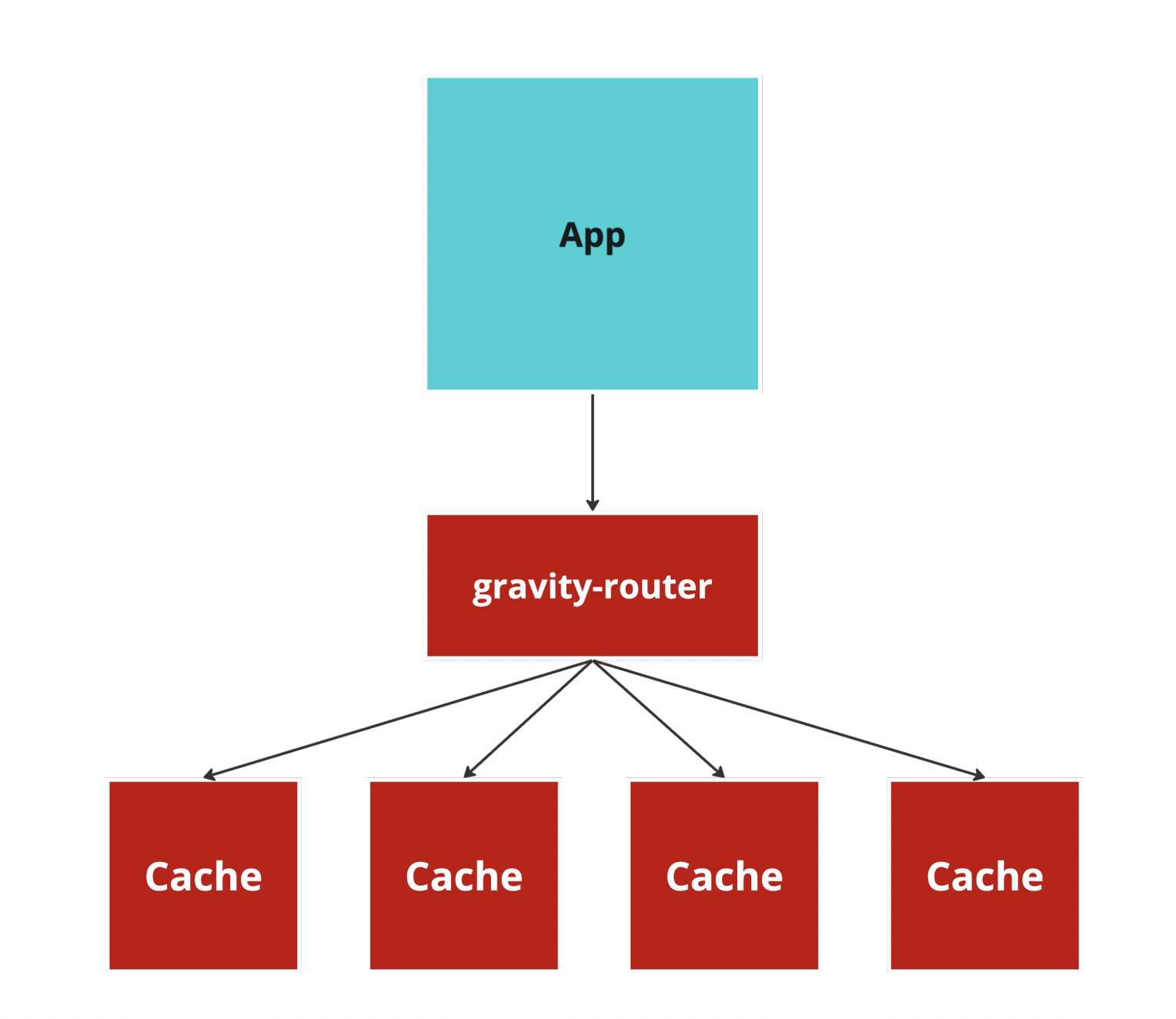
眼尖的讀者應該會說,為什麼要多此一舉用什麼 router 轉發請求?直接和 cache instance 溝通不就好了?
原因是因為假設 Application Server 有 N 台,cache instance 也有 N 台,維護一個 O(n^2) 的連線非常容易造成內部網路擁塞,所以才會透過一層 proxy 來利用。
Look-aside Problem: Stale Sets
接著我們看一下兩個經典的 Look-aside Problem,這個問題是 Stale Sets,為了方便說明請各位讀者看以下圖例。
Step.1
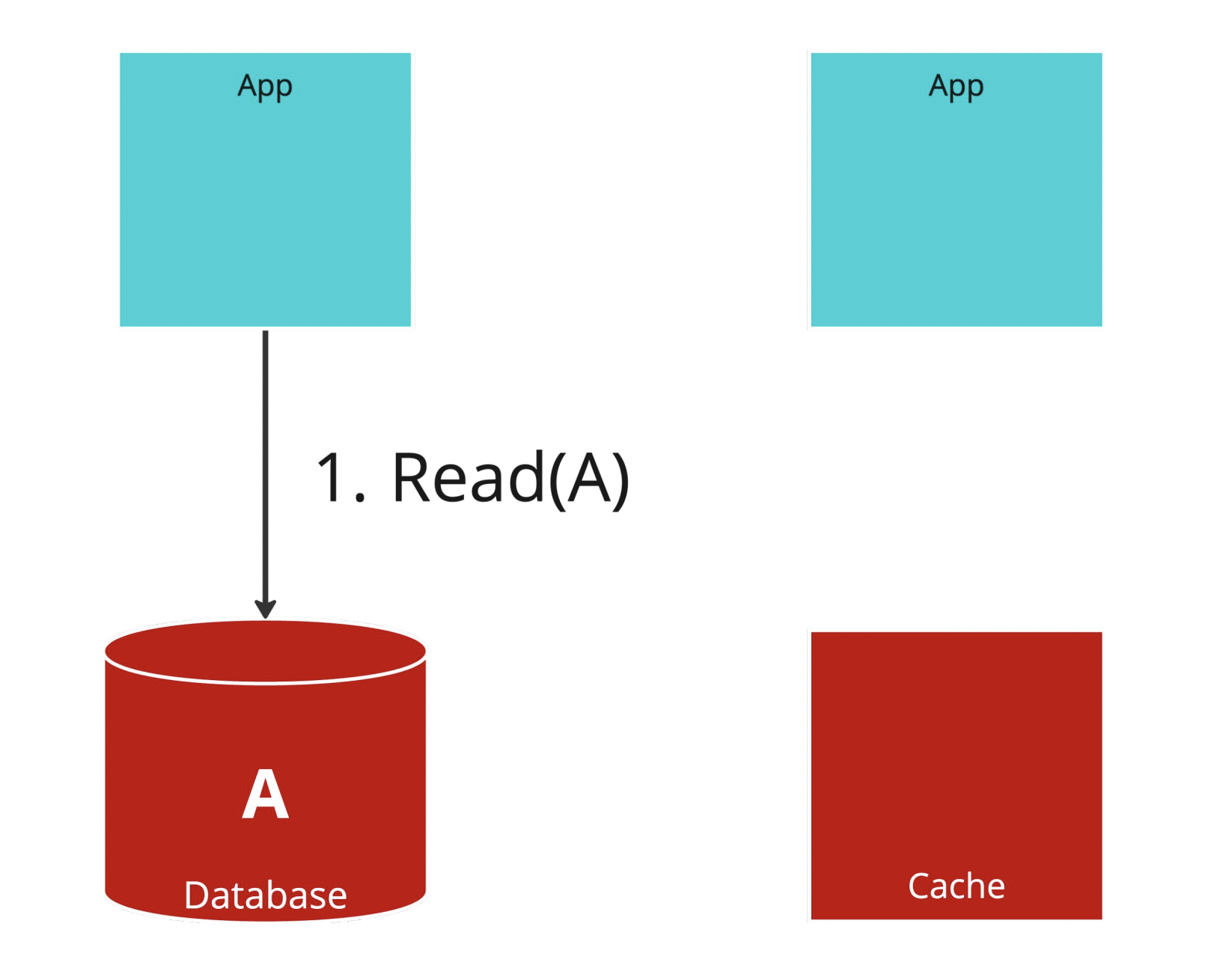 首先,左邊的 Application Server 先去讀了 A 這個資料。
首先,左邊的 Application Server 先去讀了 A 這個資料。
Step.2
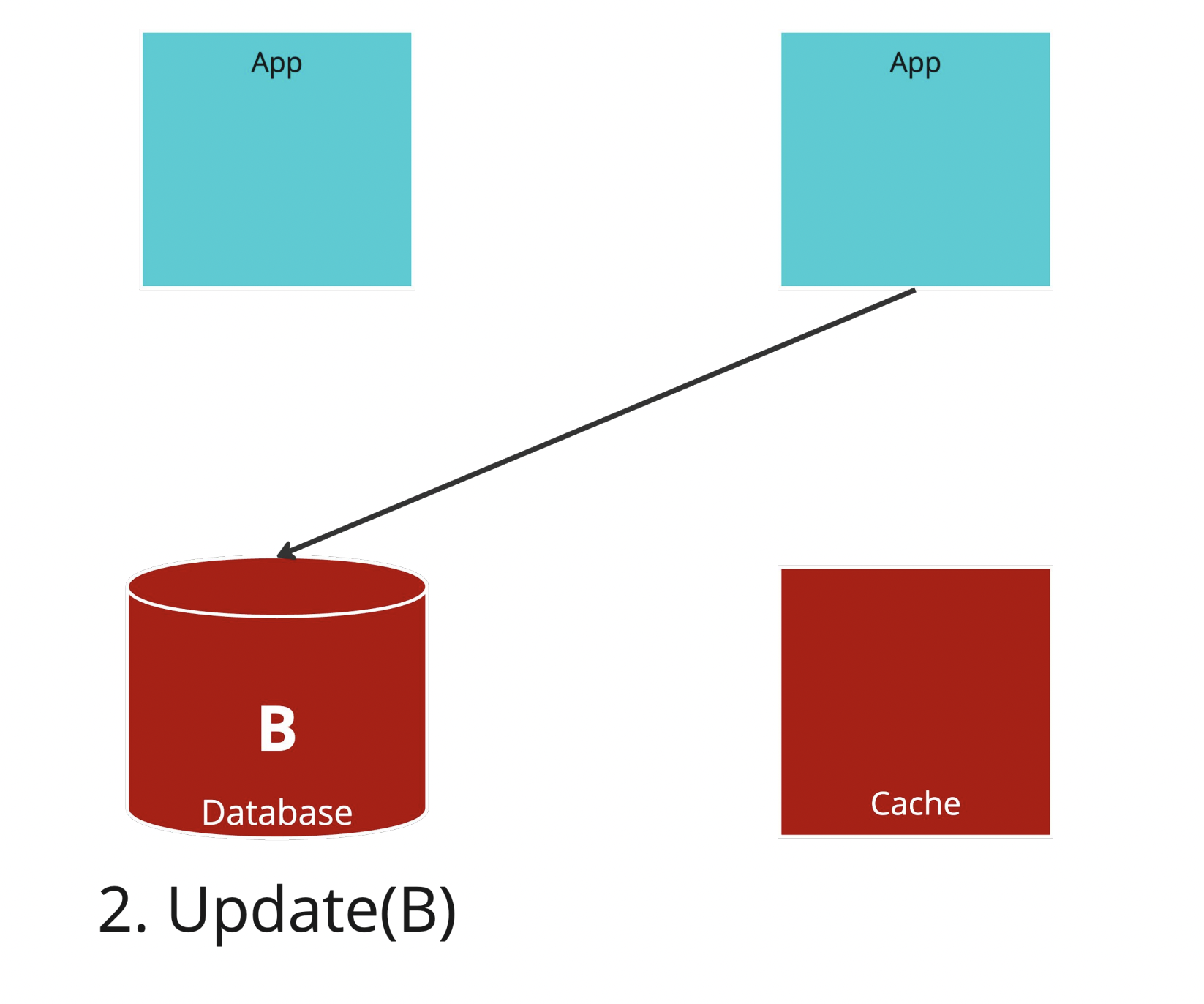 右邊的 Application Server 去把 A 更新成 B。
右邊的 Application Server 去把 A 更新成 B。
Step.3
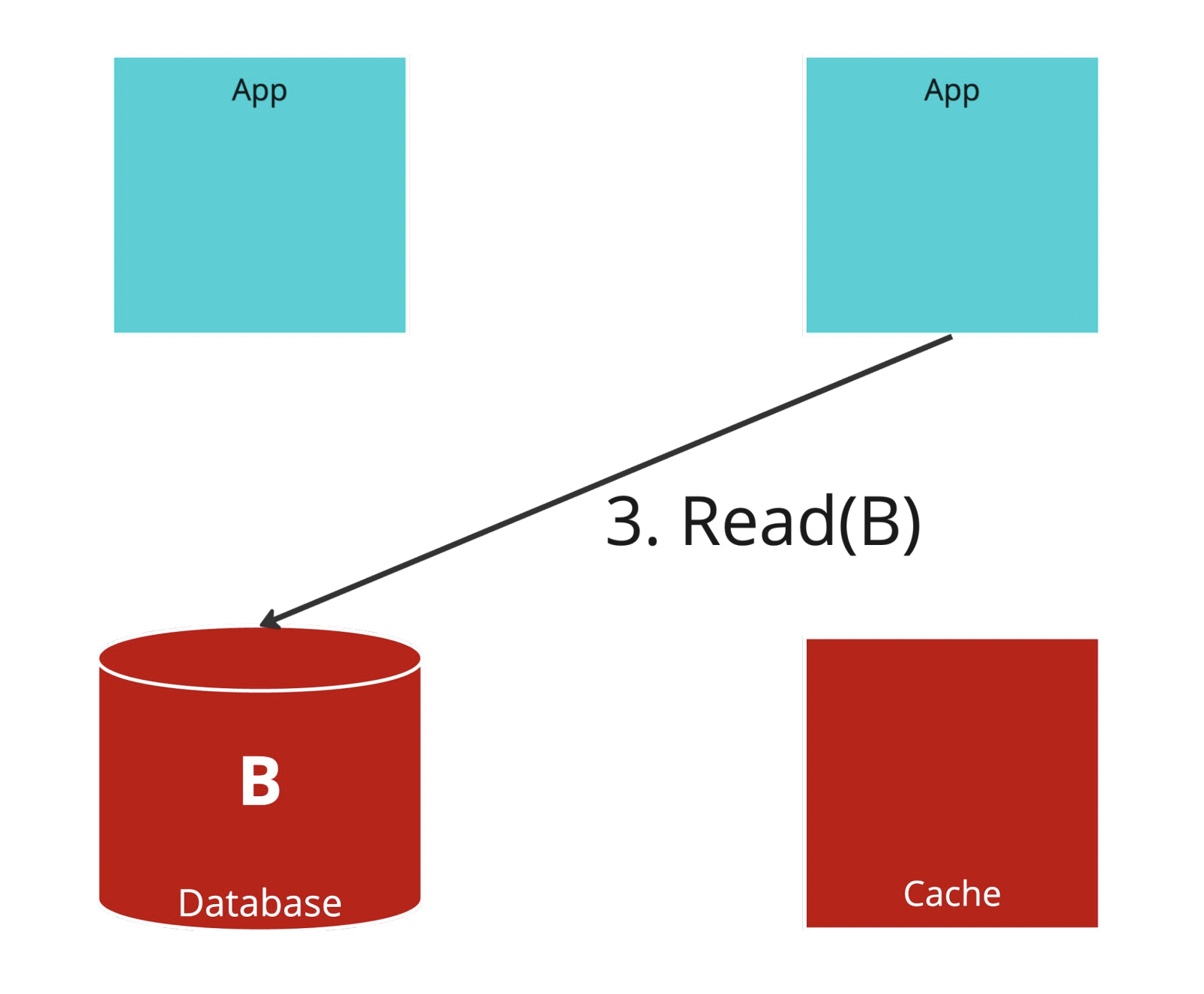 寫完之後馬上讀出來。
寫完之後馬上讀出來。
Step.4
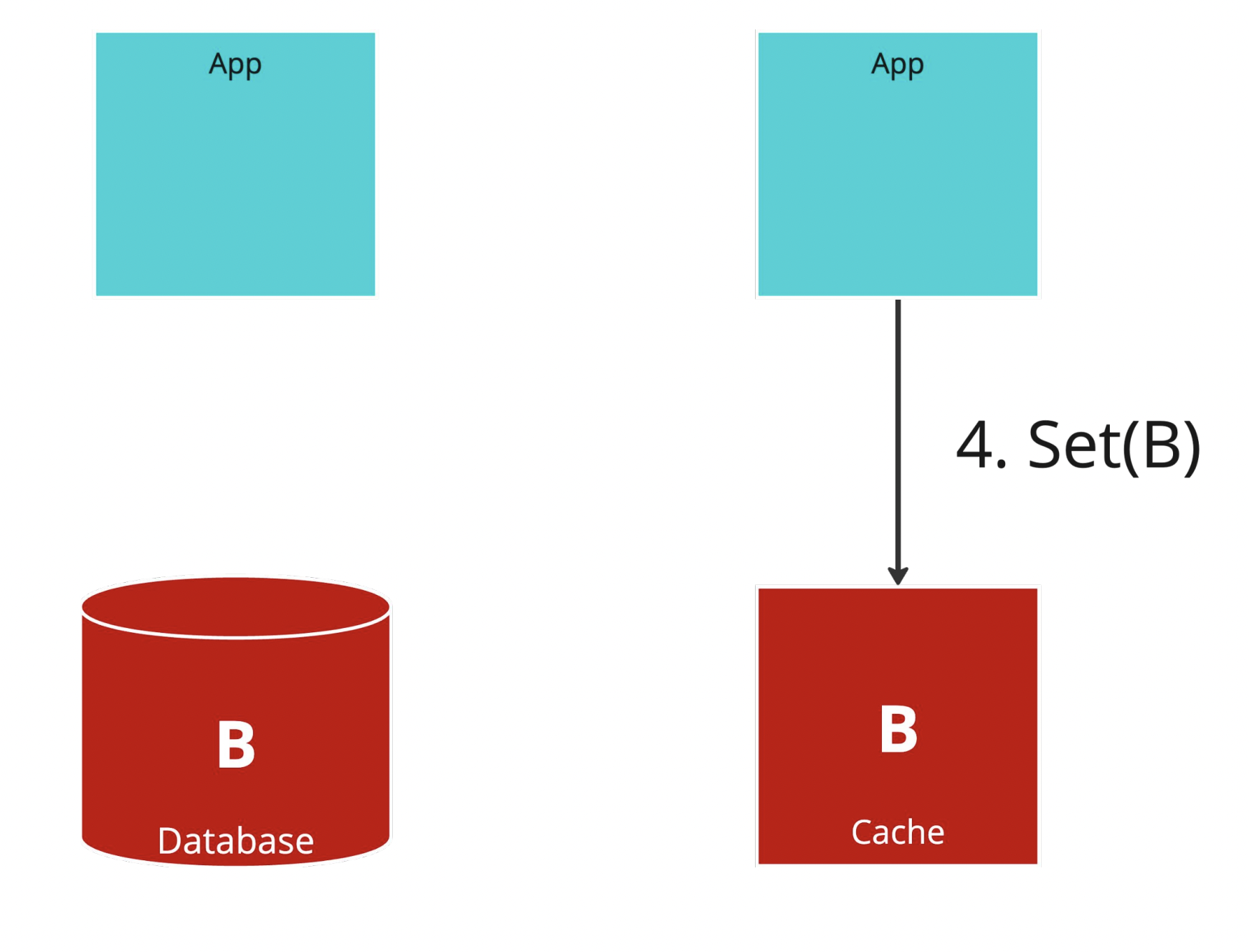 記得我們的 Policy 是由 Read 去更新 cache 嗎?
記得我們的 Policy 是由 Read 去更新 cache 嗎?
這時右邊的 Application Server 把 cache 回填了 B
Step.5
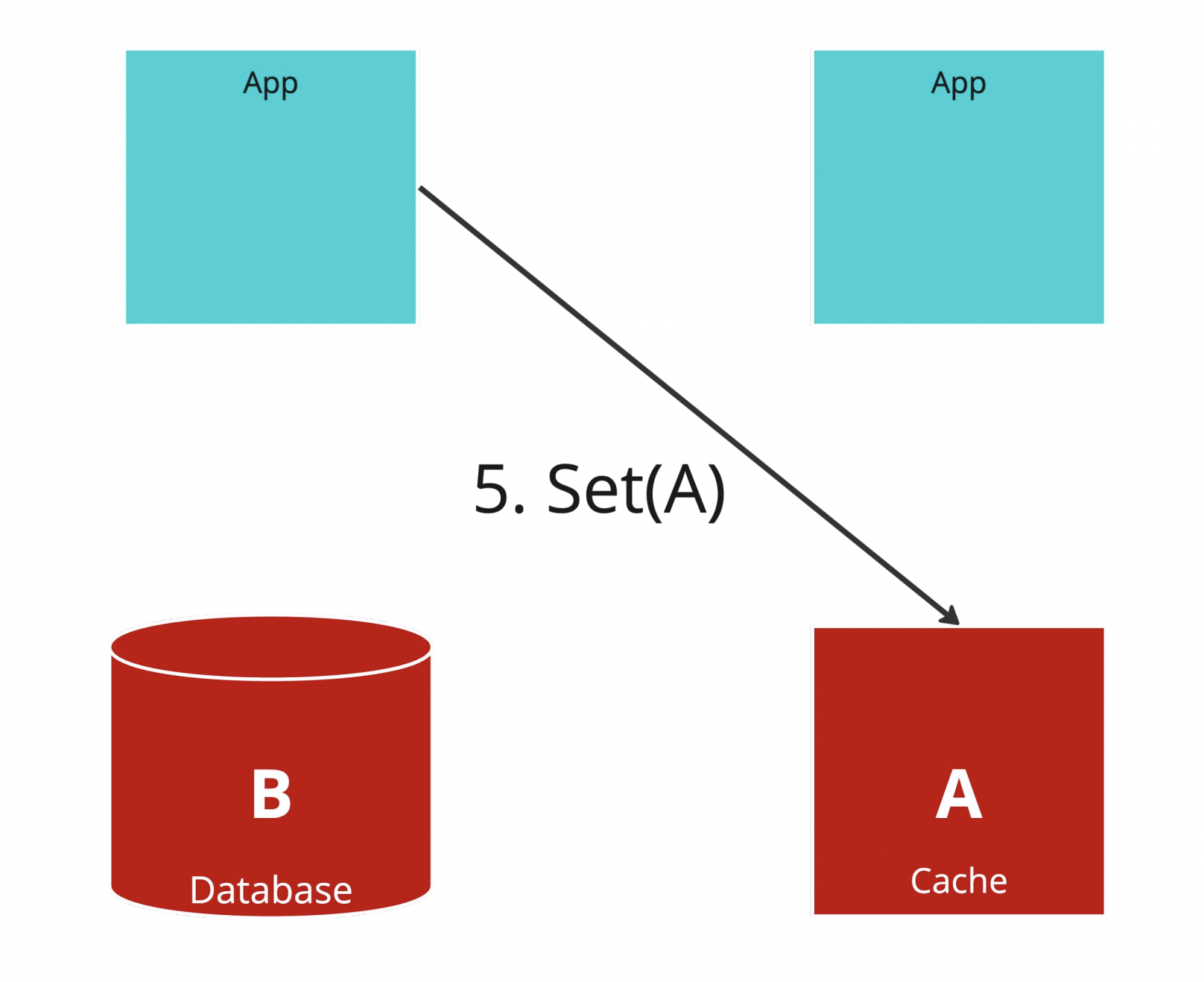
由於分布式的環境下,我們沒辦法保證不同 Application Server 的請求順序性,這個時候 Step.1 的回填才回填 cache,馬上發現一個糟糕的情況,我們的 Database 和 cache 不一致,而且到下次更新 Database 之前或是 TTL 到期之前,資料都會持續保持舊的,這確實是個嚴重的問題!
Look-aside Problem: Thundering Herds
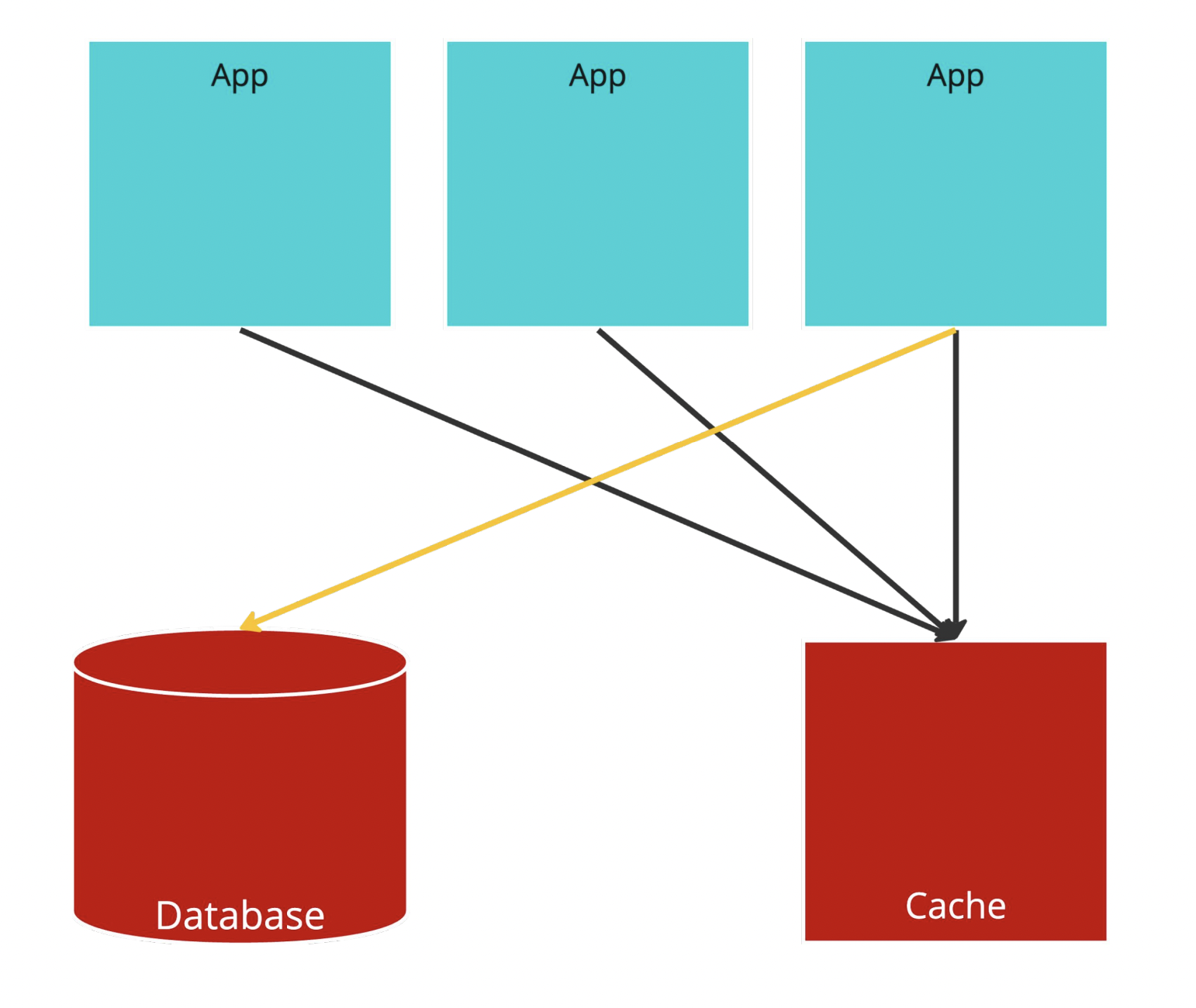 還有一個問題,就是經典的 Thundering Herds,如上圖所示,假設有一個超熱門的資料被大量的 Application Server 讀取,但是突然有一個請求執行更新,cache 被清空。
還有一個問題,就是經典的 Thundering Herds,如上圖所示,假設有一個超熱門的資料被大量的 Application Server 讀取,但是突然有一個請求執行更新,cache 被清空。
這個時候其他 Application Server 全部衝進去 Database 讀資料,基本上 Database 就直接掛給你看。
Look-aside Solution
以上提到的兩個問題都可以用 Lease 的概念來解決,Lease 的概念就是租約,,當一個請求要進入 Database 時,cache 就會發一個 Lease 給這個請求,這樣就可以同時解決以上兩個問題。
- Stale Sets: 會發現自己沒有 Lease 所以不能夠更新 cache。
- Thundering Herds: 只有那個擁有 Lease 的人可以進入 Database,剩下的請求都會去讀取那個人從 Database 拿出來的資料。
Architecture
接著我們來介紹一下整個系統的架構,分別是 Logical Architecture 和 Physical Architecture。前者是說明邏輯上怎麼運作,後者則是實際部署的架構 (這裡用 k8s 來說明)。
Logical Architecture
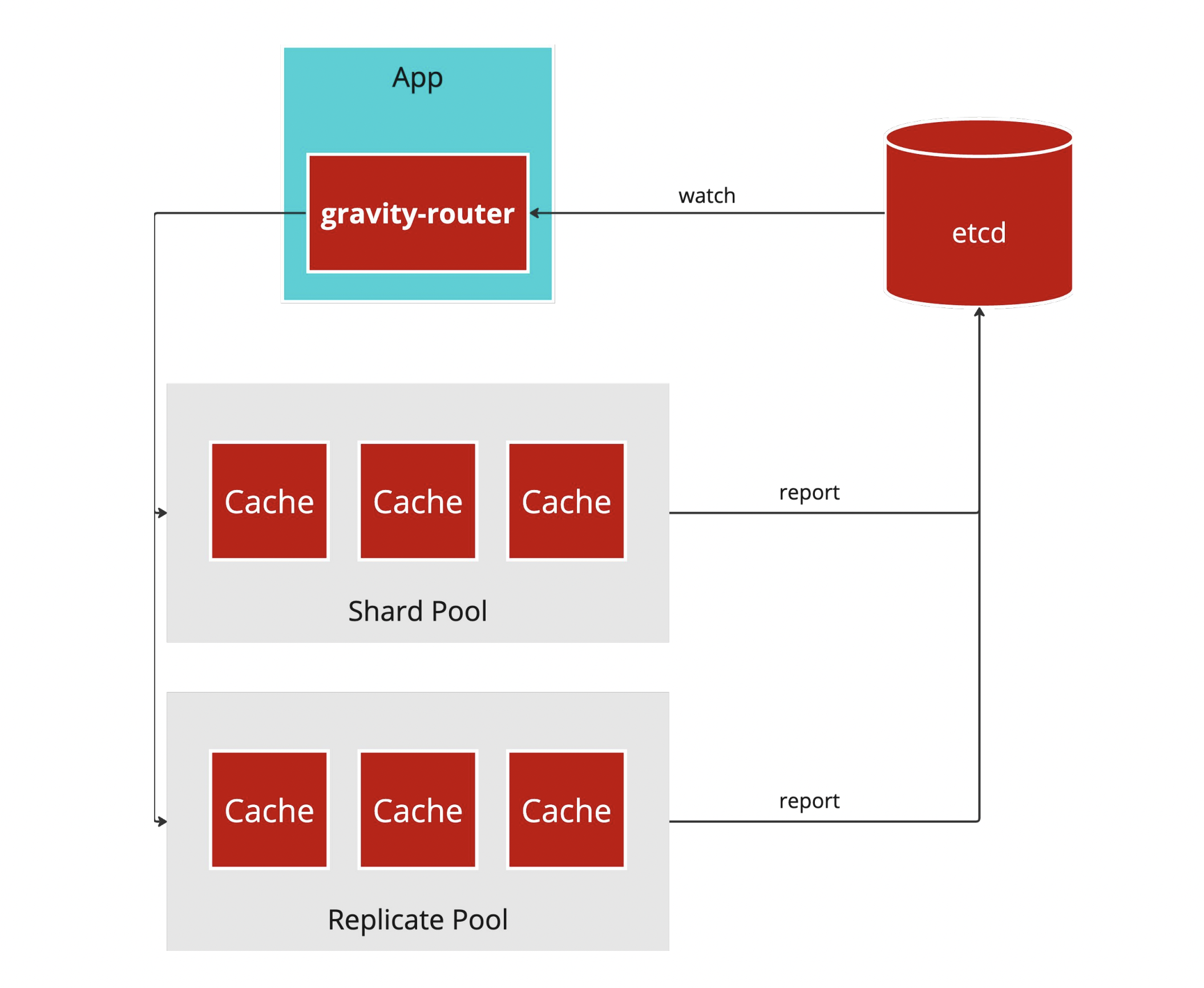
整體邏輯架構是採取兩個 Layer,底層是由 cache instance 組成的 Pool,Pool 就是一組 cache instance,可以想像成 k8s 的 Statefulset,至於兩種 Pool,對應著不同的情境。
- Replicate Pool: 所有的副本都有一樣的 cache 資料,這有兩個作用,一個是有 HA,當有其中幾個死掉還是可以繼續服務,另一個則是為熱門的資料分擔流量。
- Shard Pool: 服務大量的資料,會把 cache key 做一致性快取,平均分散到這些分片上,滿足水平擴展性。
至於 gravity-router 要如何知道 routing 的邏輯呢?
如圖所示,當部署在 k8s 上時 Pool 的大小會被更新到 etcd 中,只要把 gravity-router 用 watch API 監聽 Pool 的變化就可以更新r outing 的邏輯。
Physical Architecture
Ambassador
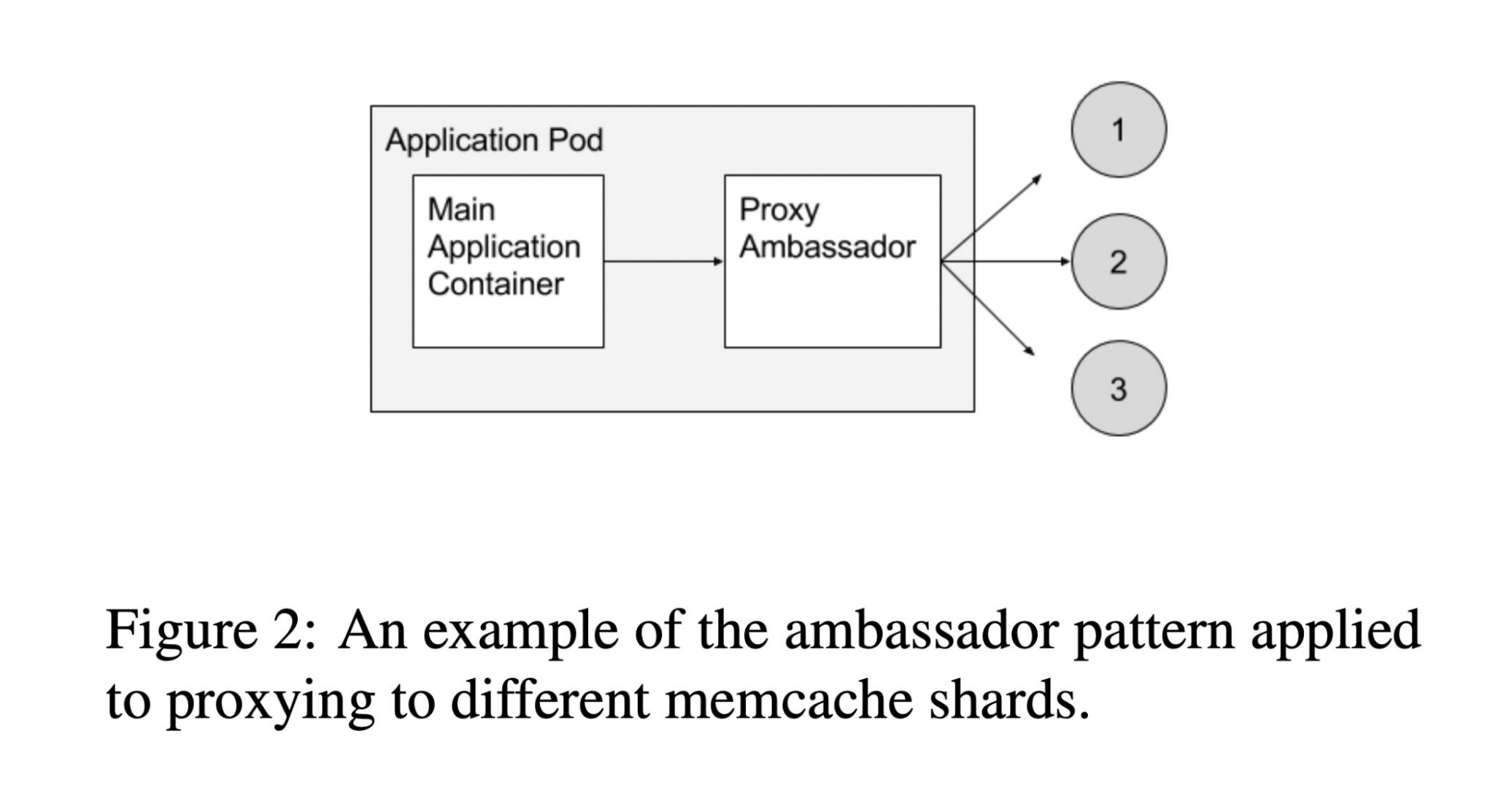
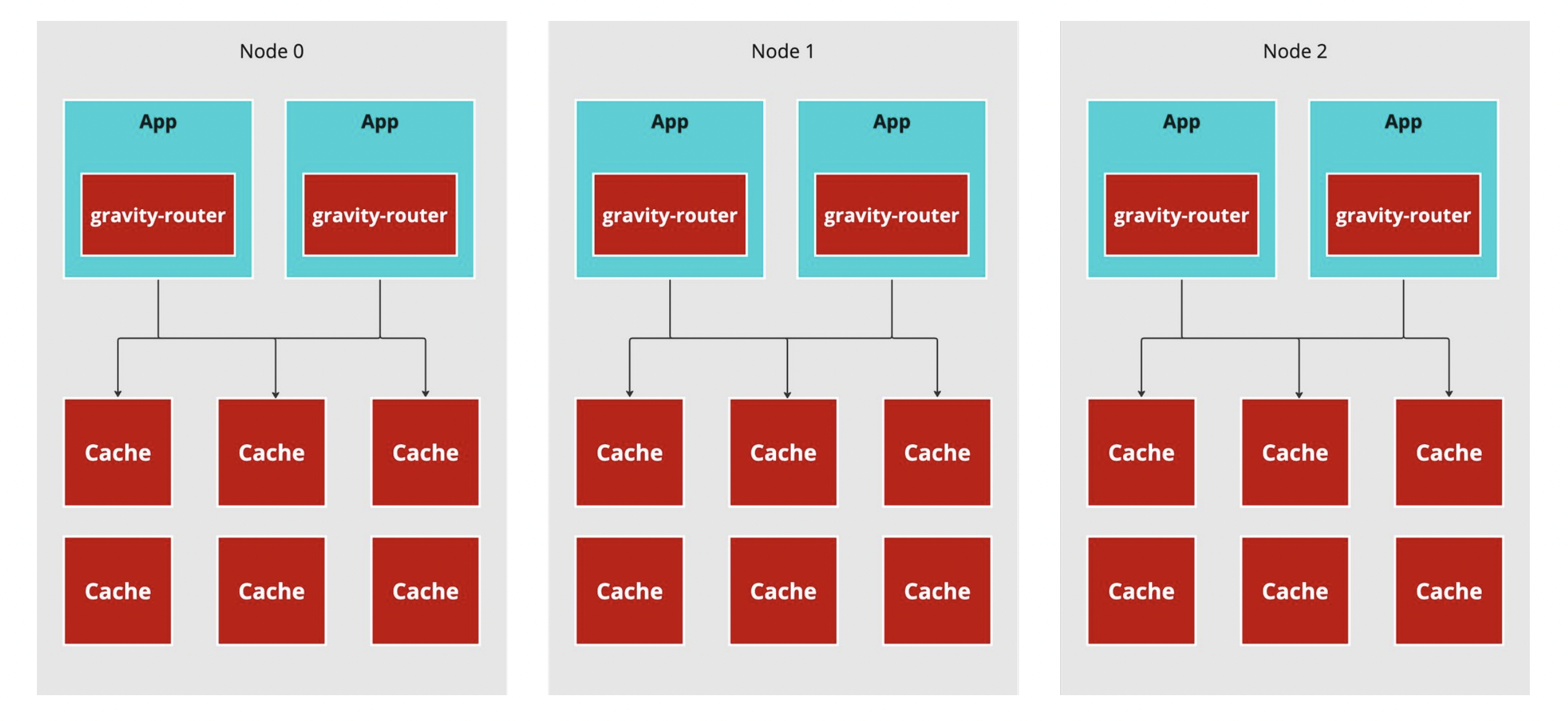 這種部署方式是採取 Ambassador 這種 Pattern,在同一個 Pod 內部放一個大使容器,所有的請求都會由大使容器負責。
這種部署方式是採取 Ambassador 這種 Pattern,在同一個 Pod 內部放一個大使容器,所有的請求都會由大使容器負責。
這種方法是參考 k8s 作者所寫的一本書中提到的概念,興趣的讀者可以買來參考。

如果想要快速參考這個概念,可以閱讀 Design patterns for container-based distributed systems 這篇論文,其實上面那本書就是這篇論文寫成書,講的內容大同小異喔 XD。
DaemonSet
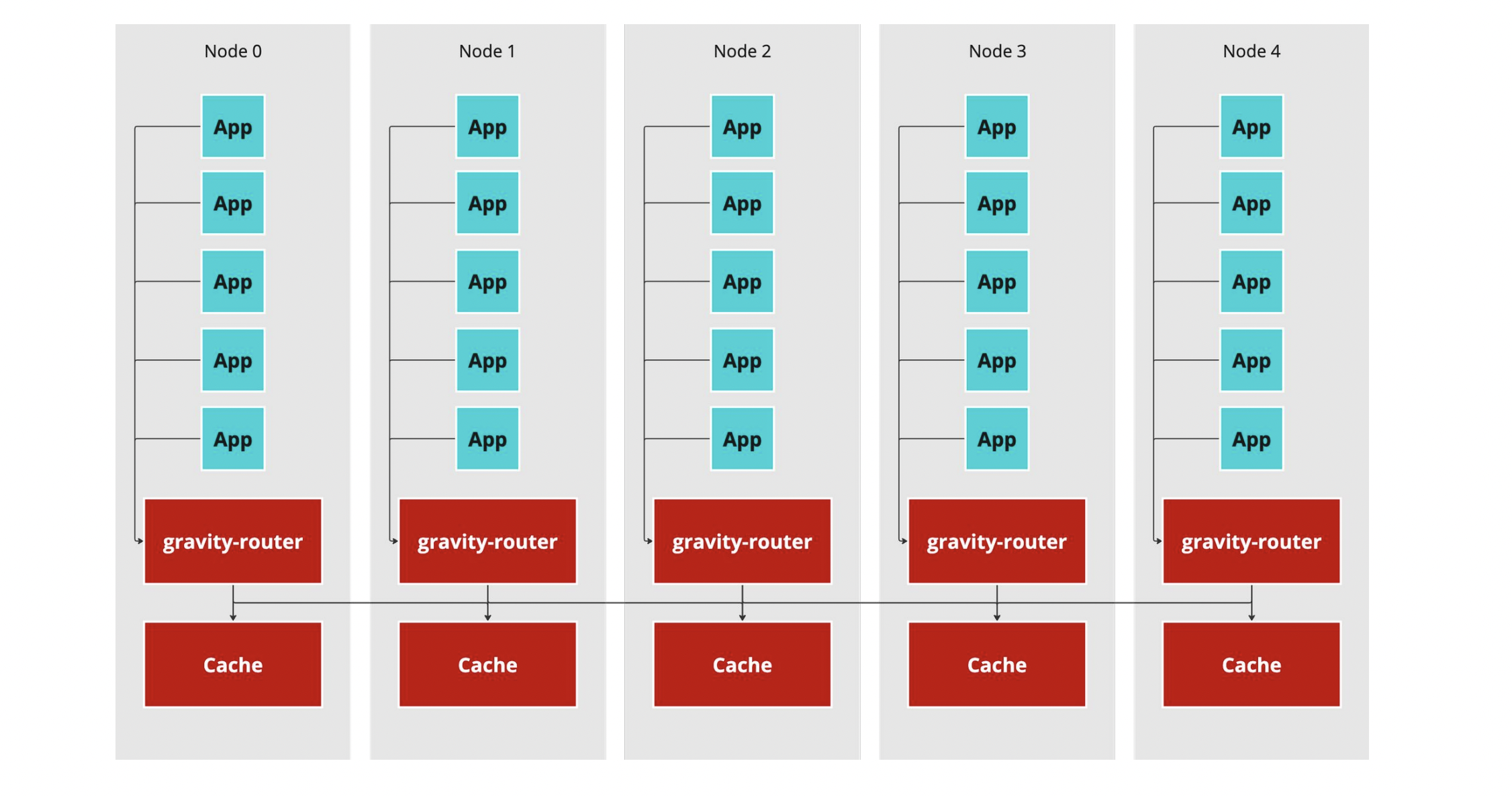
這種部署方式則是效仿 GKE 的部署方式,在每一個節點上種一個 router 和 cache,所有該節點的請求都由 DaemonSet 負責處理。
Implementation
Router
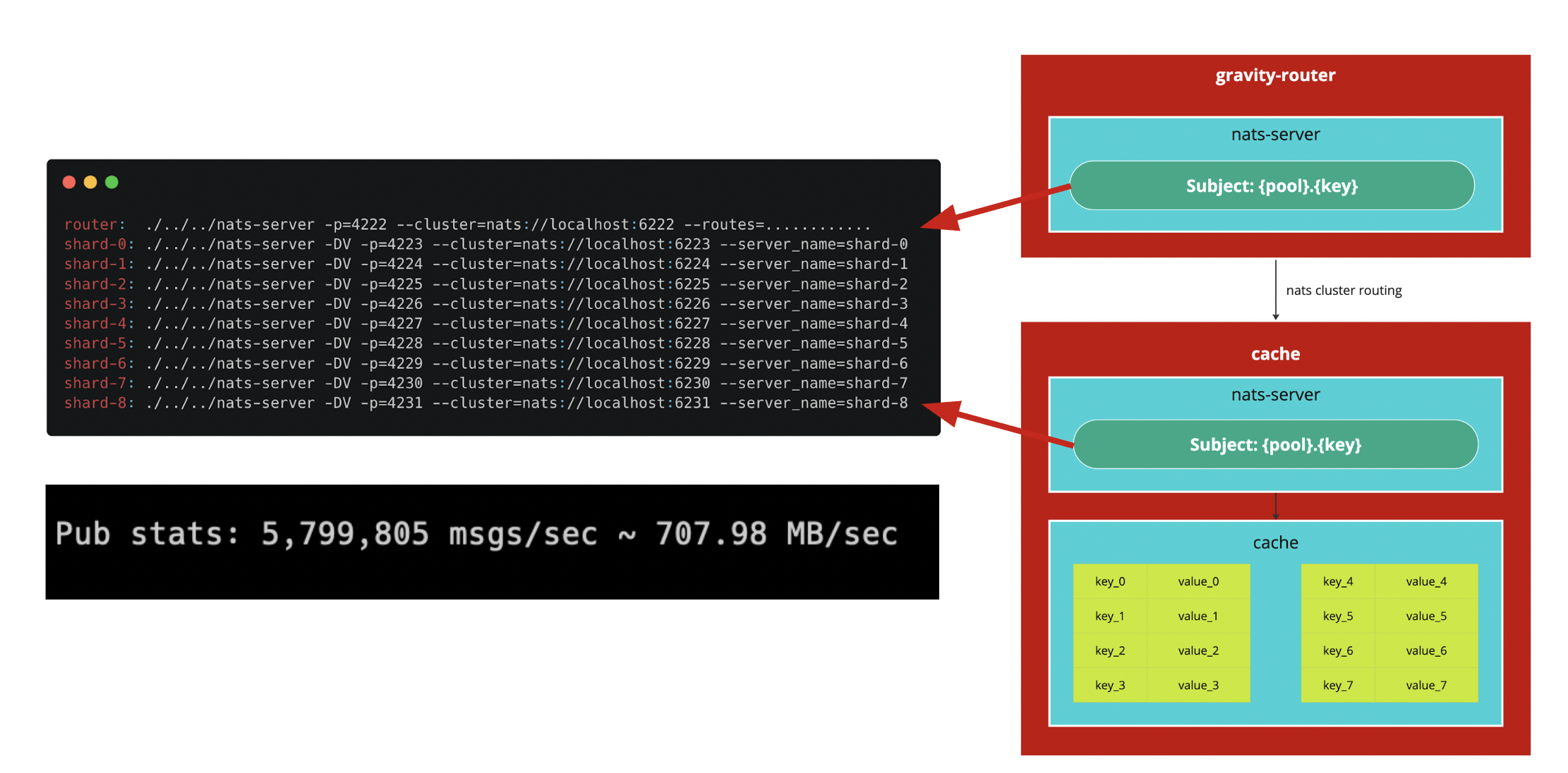
Router 的設計利用 NATS 這種 Message Broker,來做請求的轉發,router 和 cache 用這個功能來做廣播。
Cache
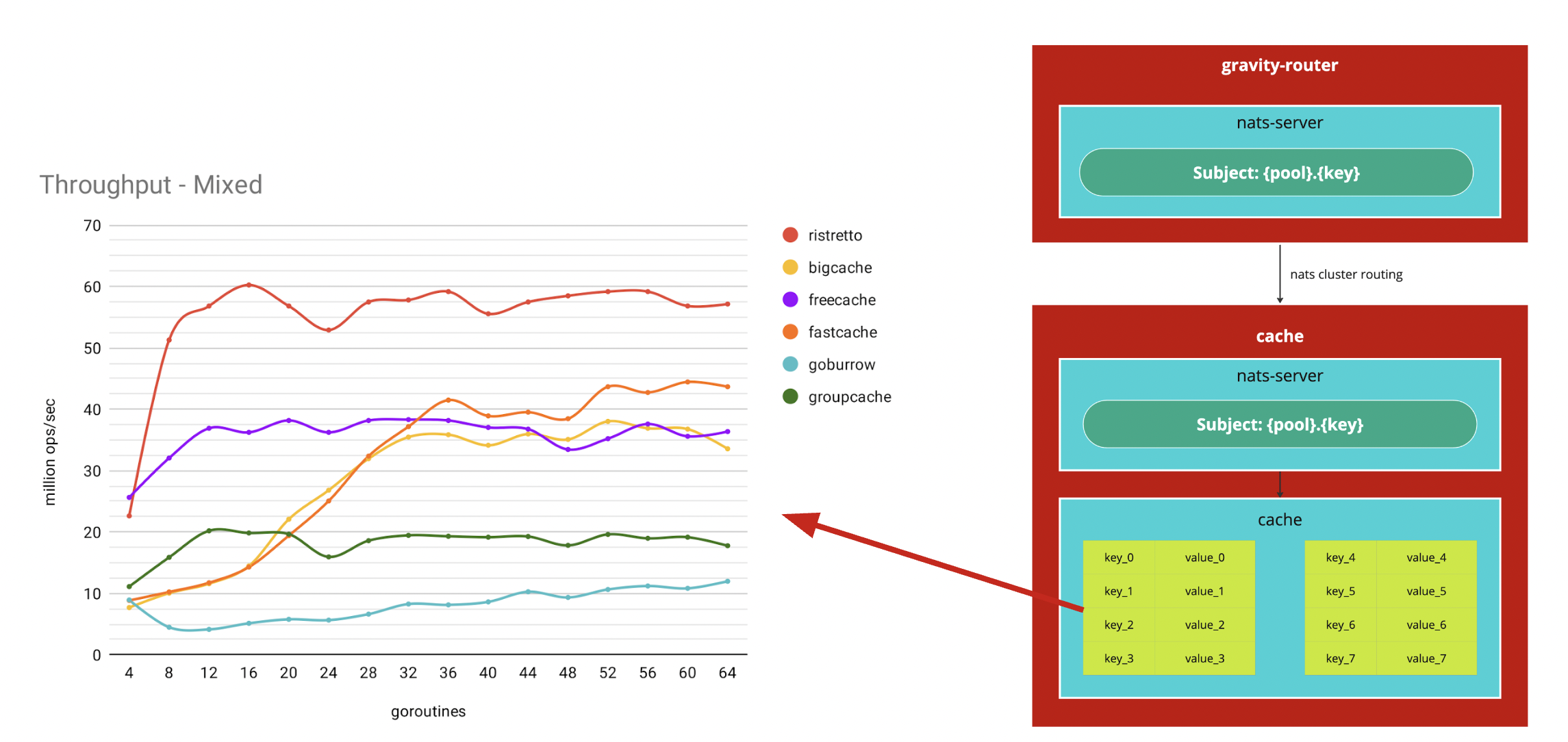
至於 cache 也十分簡單,我用一個經過實戰測試的高效能 cache 來訂閱自己需要處理的請求,詳細可以參考 dgraph-io/ristretto。
Process
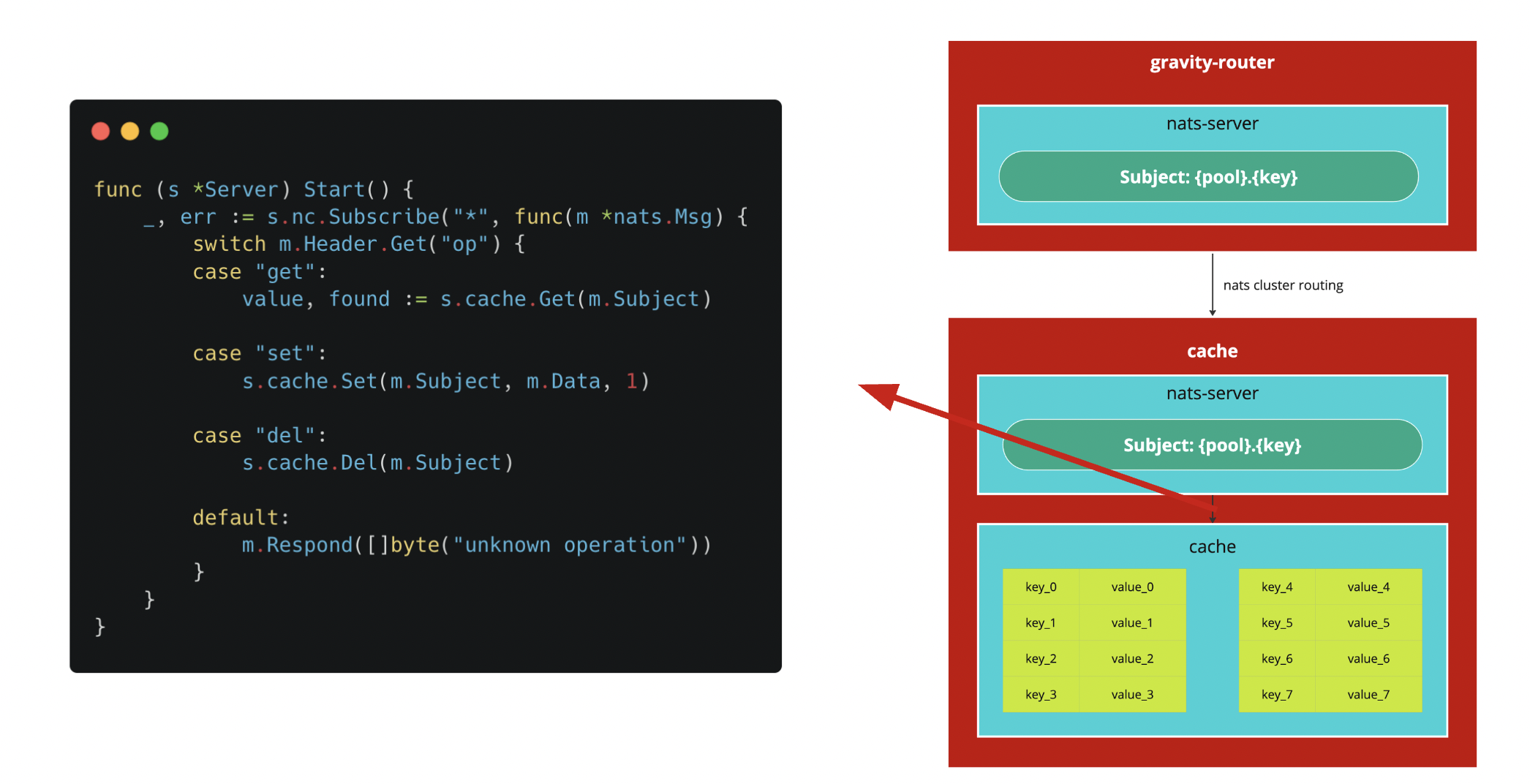
Process 的邏輯是則是建立在 NATS 的訂閱機制下:
- Key: 由 {pool}.{key} 顯性表示
- Value: bytes 則是夾帶在 Message 的 Payload 中。
- Operation: 支援 Key-Value 的操作,夾帶在 Message Header 中,藉由判斷 Header 來決定處理方式。
Lease
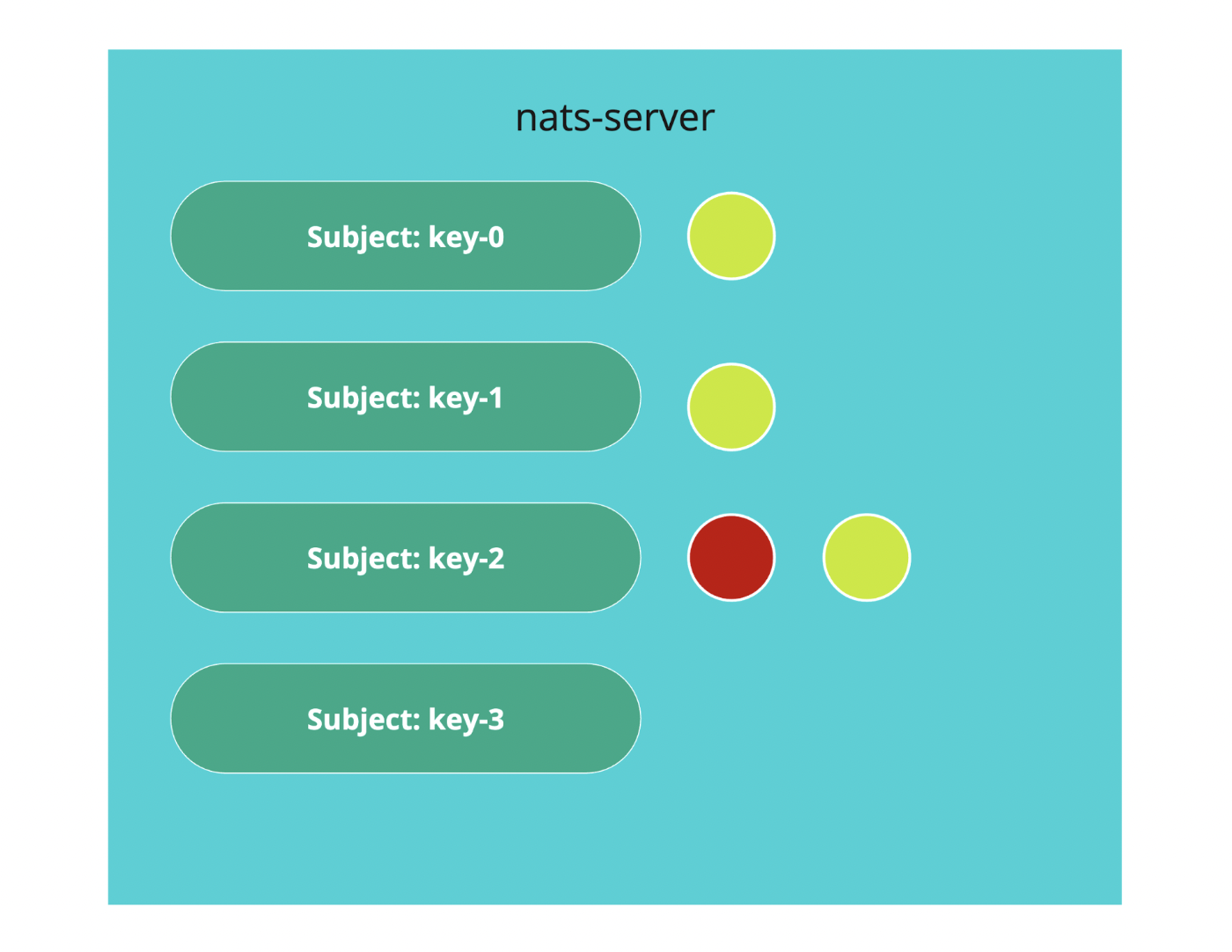
Lease 實作則比較有趣,NATS 有支援一個功能叫做 DiscardNewPerSubject,對於每一個 Subject 可以指定最多可以容納多少訊息,當有內部沒有消化完時,就會拒絕多出來的訊息,算是一種 Optimistic Concurrency Control,詳細可以參考這個 部落格。
Client
Client 則是實作在 NATS 的機制上,大幅利用 Sync/Async 等訊息機制,舉例來說: Set() 操作可以用 Broadcast 的發送給下游的所有 instance,等到特定數量的回覆就可以回傳成功,你可以決定要用候選人數量或是所有數量都可以。Get() 可以用 Canary Request 或是 Hedged Request 來達到你想要的效果。
Canary Request 和 Hedged Request 是 Google 最頂尖的科學家 Jeff Dean 提出的方法,被廣泛運用在 Google 的服務上。
Canary Request 是模擬金絲雀,假設下游由數台 Server 請求會先呼叫其中一台,然後等一段小時間,比如說 5ms,如果沒有回應就呼叫另外一台,失敗特定次數後就放棄。Hedged Request 也是差不多概念,運用大量的 Server 來平攤效益,反正有幾個副本就撒 Request 下去,看誰先回來就好。
這兩種方法都可以大幅減低 Latency 尤其是 P99 Latency。
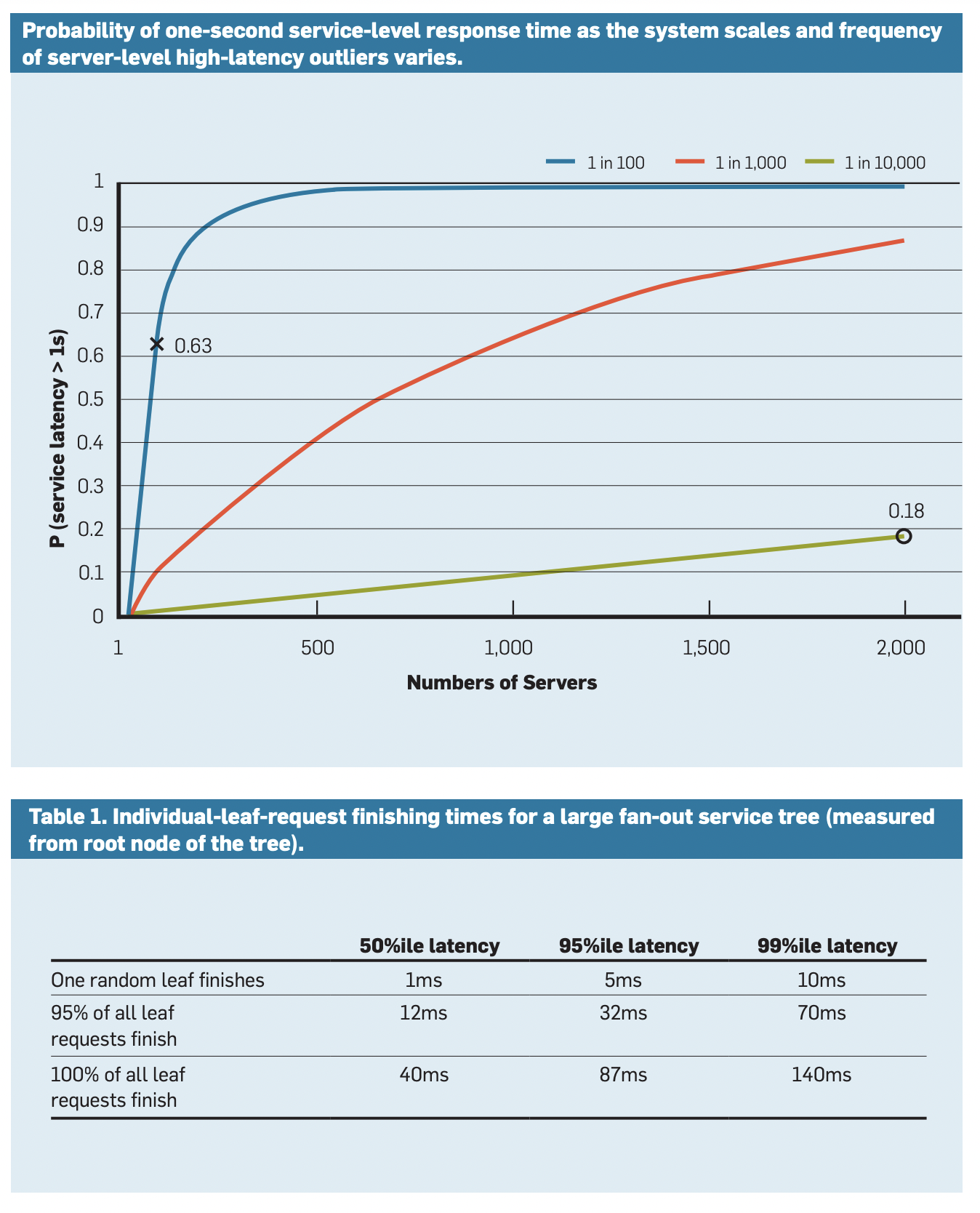
詳細可以參考 The Tail at Scale 這篇論文。
心得
這實作真的非常好玩,以前覺得看懂論文到真的做出一樣效果的東西少說一個月起跳,不過這次經由選擇一些成熟的套件花點心思就可以把整套 facebook 的 cache 給拼出來,成就感頗高,而且還能學到很多東西。而且發現寫服務層用 NATS 真的是很方便,以前用 gRPC 拼個老半天 code 還很醜 QQ