<Notion 的 Data Model & Sharding Postgres>

Index
簡介
這篇文章會統整 Notion 兩篇非常重要的工程部落格,分別是 <The data model behind Notion’s flexibility> 和 <Herding elephants: Lessons learned from sharding Postgres at Notion>,其簡單扼要地講述了 Notion 背後的工程設計,我一向喜歡研究自己覺得很好用的工具怎麼設計的,就讓我們來看看吧。
Notion 是啥?
對於不知道 Notion 的人我想還是有的,它是一款功能非常強大的線上筆記軟體 (甚至可以說是資料庫),我會用來整理幾乎所有我目前在研究的東西。
甚至我寫這篇部落格的草稿也是在 Notion 上而不是 VScode。
(雖然我沒收 Notion 錢,但是 Notion 真的是個好軟體)

Blocks
Blocks 的 Schema
這邊建議可以先去創個 Notion 帳號,然後邊玩玩看邊搭配我的文章理解,應該不難發現 Notion 使用起來很直覺,你可以把資訊塊拉來拉去、重新組合,就像是樂高一樣!這些資訊小碎片,在 Notion 裡面稱作 Block,每一個小碎片都有以下五個屬性。
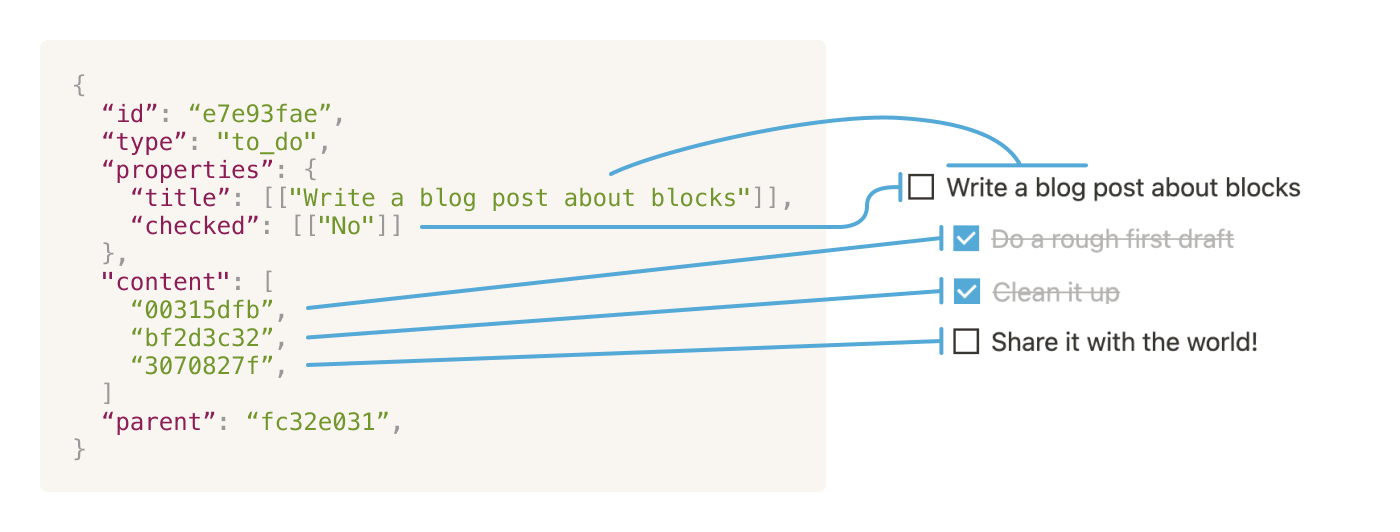
- ID:唯一的編號,就像每個 Block 的名字,用 UUIDv4 亂數生成的。
- Type:這個 Block 是個什麼樣的 Block (如下圖,Type 就是 Text, Page, To-do list …etc)。
- Properties:一些屬性,像是 title 之類的,如果是比較特殊的 Block,Properties 就會長的比較不一樣。
- Content:主要是一個 Array 紀錄這個 Block 裡面有什麼 Blocks。
- Parent:這個 Block 的 Parent,主要用來管理權限。
Blocks 的特色: Dynamic Change
你可以發現 Notion 可以自由的變換顯示的方式,比如說原來的 H1 你可以換成 H2 或純內文,主要就是 Content 本身設計上和 Type 互相獨立,Properties 本身不會因為你更改 Type 而變,只是 render 的時候不會顯示出來。(有就意味著你把 Checkbox 改成 Header 然後改回來,打勾的屬性還是會記錄著)。
Blocks 怎麼組裝和運作起來呢?
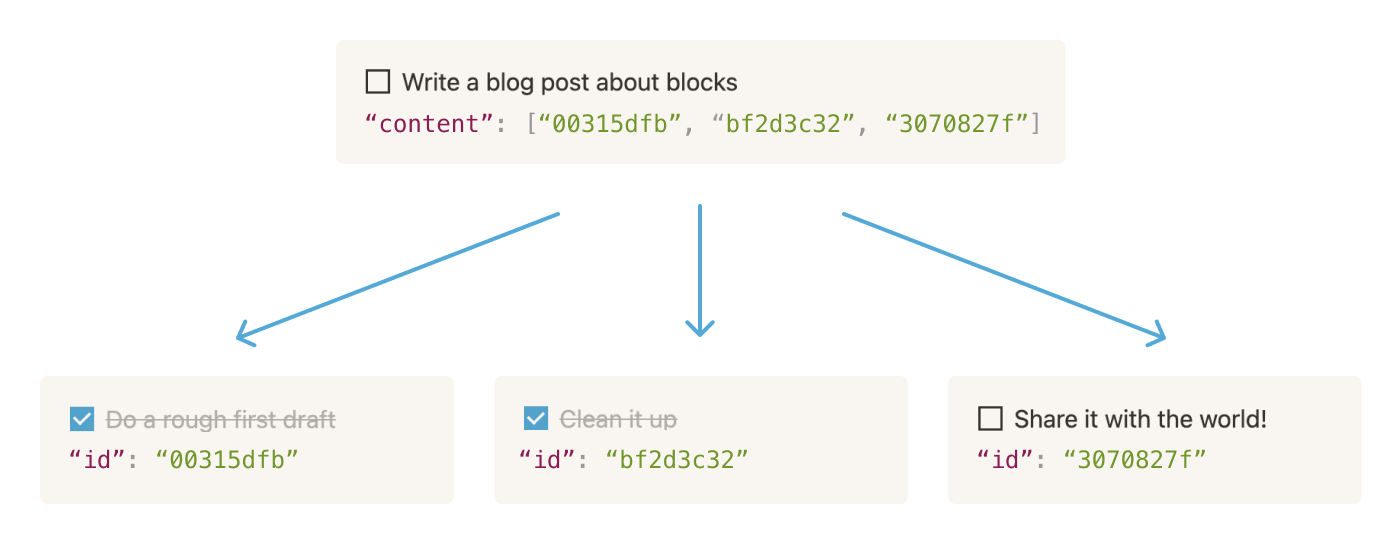
Render Tree
Notion 屌的地方在於,除了多樣化自由變動的 Block,還可以無窮的巢狀去組織它。Notion 稱作個設計叫做 Render Tree,實作方式也蠻好理解的(對於 CS 背景的來說…),用剛剛上面講的 ID 當作指標,指過去就好了。
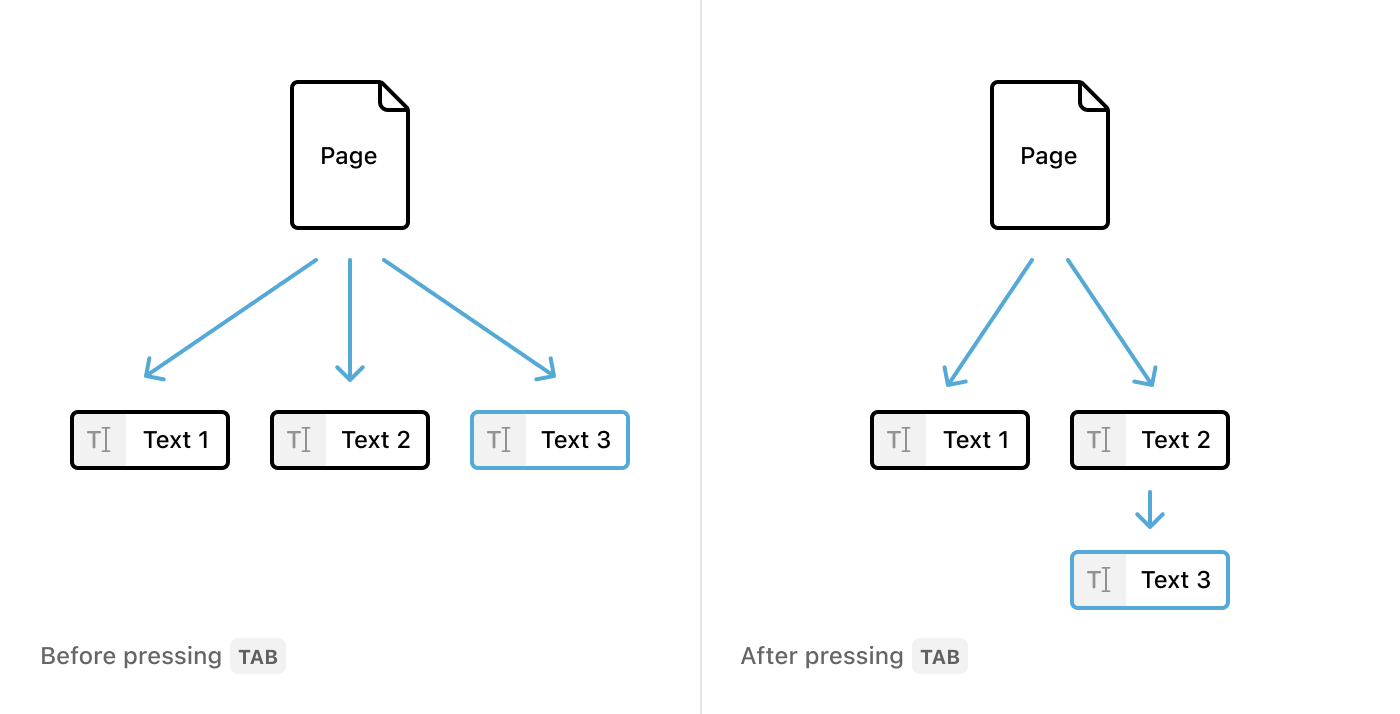
Indentation
至於 Indentation 則是直接操作 Render Tree 的結構,所以並不是單純的加上甚麼 Tab 字符,而是直接操作整個 Block。
Permissions
Notion 還有一個特點,就是可以分享 Blocks,最終他們使用參考 Parent 的方式,舉例來說,如果你要讀某行文字,你必須取得這行文字 Page 的權限。
一開始原本打算用多個 content arrays 去管理,但是這種方法導致 Blocks 互相參考會有模糊空間,所以最終還是採用 Parent 這種方式。細節上,只記錄 Parent 用來給 Permission Service 驗證,Parent 則指紀錄自己有哪些 Sub-Content。
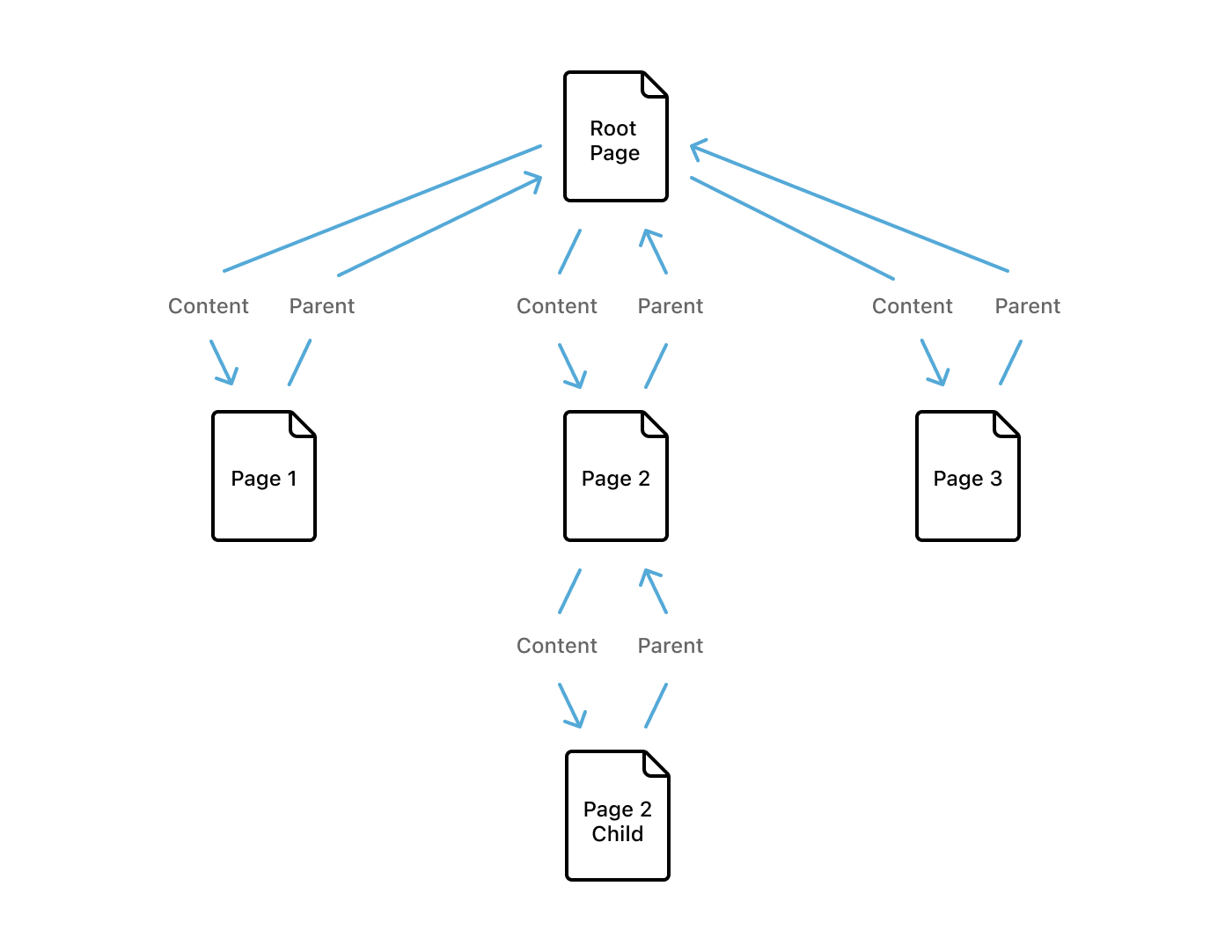
Block 的生命週期
Creating and updating
一個 Block 的生命週期出始於 User 建立,後續的每一個 Block 操作都會被 Batch 起來,變成 Transaction,再看看是要 commit 還是 reject。
舉例來說,如果你建造一個新的 Block 除了你增加的內容本身,還要改寫這個 Block 的 Parent,這些都要變成一個 Transaction。
對 Client 來說,當他們修改內容的時候,都會被 Cache 起來,實作上 Notion 有說用 SQLite 或 IndexedDB 做 Cache (取名叫做 RecordCache),至於遠端的操作都會寫入 TransactionQueue 最終同步到遠端的資料庫,至於 TransactionQueue 則是實作在 SQLite 或 IndexedDB (看你是哪個平台,網頁端或是行動端)。
正常來說,TransactionQueue 都是空的,只要 Client 有任何操作,Transactions 會打到 /saveTransactions 這個 Endpoint。後續操作也沒有超出大家的想像,API server 就把這些操作做完回個 HTTP 200,然後執行下一個 TransactionQueue 的工作。
在背景還會做一些額外的工作像是 version history snapshots、Quick Find 的 Index、還有紀錄你做的任何改變到 MessageStore Service。
Real-time updates
那和你分享 Block 那端的朋友是如何看到更新的呢?
對於每個 Client 都會維護一個 long-lived WebSocket 到上面講的 MessageStore Service,當 Transaction 已經完成的時候,就會通知 MessageStore Service 上面所有訂閱的 Client 就會拿更新的資訊去更新自己 local cache。
Reading blocks
這部分我覺得相對簡單,設計上不會一次全部都 load 進來,而是用 loadPageChunk API 把後續一些 Blocks 加載進來,然後用 React render。
Sharding
上面就是概略的 Notion 模型,接下來我們進入一些更技術的環節,Sharding!
會進到這個步驟其實是一個重要的里程碑,因為代表公司的使用人數已經到了一個數量級!工程上的轉折點則是當使用 Postgres VACUUM 開始出現問題的時候,Infra Team 會常常需要處理就可以開始準備 Sharding。
Notion 做終決定使用 Application-Level Sharding,也就是在 Application Logic之內做 Sharding,雖然一開始有考慮 Citus 或是 Vitess 之類的產品,確實簡化了 Sharding 的過程,但是對於 Clustering 本身的邏輯卻變得不透明,所以還是選擇上述的方案。
Sharding 要考慮的問題
當決定好 Application-Level Sharding,接下來我們探討三個主要的決策。
要 Sharding 什麼 Data?
對於 Notion 來說,block Table 是最主要的核心,我們只需要 Sharding 特定的 Table,並且保存其餘資料的 Locality。
要怎麼 Partition?
必須要選擇一個特定的 partition key 去拆分資料,這個 key 要能夠均勻的分散在各台機器之上。因為 Distributed Transaction 和 Join 都是被限制在 single host。
實際上要建立多少個 Shard,然後我們要怎麼管理?
這個問題其實蠻明確的,比較工程的觀點就是要怎麼 mapping logical shards 和 physical hosts。
Sharding 的解決策略
接下來我們就一一討論解決方案
Decision 1:以 block 為中心 sharding
由於我們的 Data Model 圍繞著 block,每一個 block 都是 database 的一個 row,block 擁有最高的 sharding 優先權。然而,block 本身會連接到其他的 table,像是 space 、discussion、comment。
所以我們決定把 sharding 所有 block 會接觸到的 foreign key table。
並不是所有的 table 都需要 shard 但是如果一個 block 有關的 block 本身放在不同的實體機器,我們就不能有 transaction 的保證。
舉例來說:一個 block 儲存再一個 database 中,但是和它有關的 comments 卻是放在另一個 database,當我們刪除這個 block 就不能保證 comments 能夠 transaction 的被刪除。
Decision 2:用 workspace ID 來 partition
由於 Notion 是屬於 team-based 的產品,下一個決定的就是要用 workspace ID partition。
每一個 workspace 建立時就會有 UUID,我們可以根據 UUID shard 進去統一的 buckets。由於一個 block 只會屬於一個 workspace,所以 workspace ID 就是我們的 partition key,這避免了 cross-shard joins 這種昂貴的操作。
Decision 3:能力綜合評估
大致有以下的評估重點
- Instance type:選 AWS 機器的重點是 IOPS 經由估算大致需要 60K 的 IOPS 。
- Physical 和 Logical shards 的數量:經由評估 RDS 的數量,為了確保 replication 的有效性,每個 table 最多 500G,每台機器則是不超過 10TB。
- 機器的數量:越多的機器固然要花越多成本去維護,但是系統也會變得更強大。
- Cost:要求 scale linearly,可以方便估算大小。
Sharding 的實際解決方案
最終我們選擇了 480 個 logical shards,32 台實體機器,實際上的結構如下:
- Physical database (32 台)
- Logical shards (15 per database,總共 480 個)
- block table (每一個 logical shard 有一個,總共 480 個)
- collection table (每一個 logical shard 有一個,總共 480 個)
- space table (每一個 logical shard 有一個,總共 480 個)
- etc (不一一羅列)
- Logical shards (15 per database,總共 480 個)
接下來的解釋我覺得是本文中的精華,有點直覺的人可能會問 “480?”,我以為在計算機科學裡面都是用 2^n 之類的ㄟ!主要的因素是 480 有很多的因數!
舉個例子來說,如果選 512,當我需要調整實體機器數量的時候,要從 32 → 64,跳太多了,但是用 480,跳的間距就不是那麼大,所以選因數多的就是個不錯的選擇!
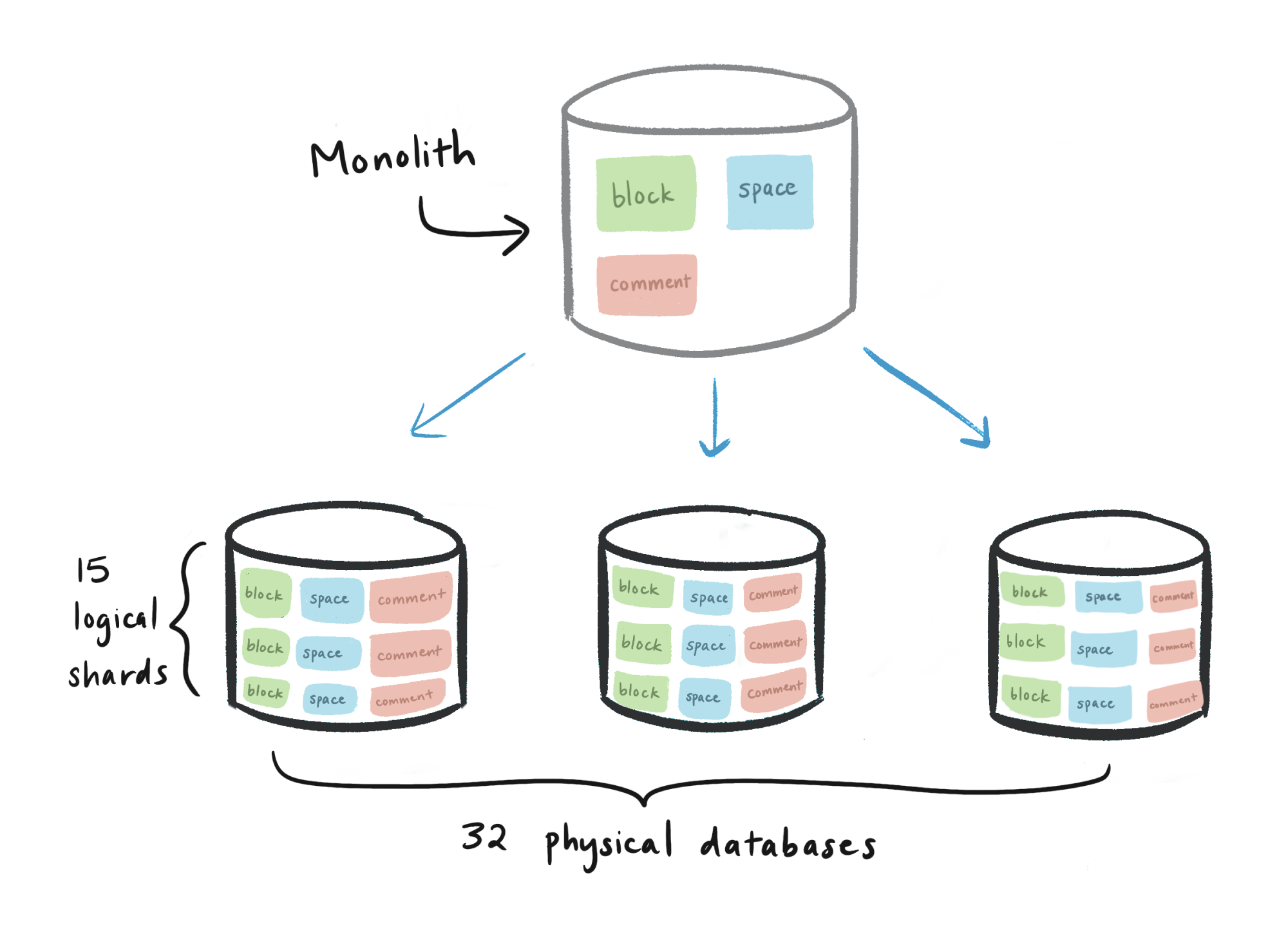
所以在 database 上可以看到的 table 會是像 schema001.block, schema002.block …etc,我們直接當 separate tables 來處理,而不是在每一個 database 維護一個 partitioned block table 然後有 15 child tables。
我們的 routing logic 如下:
- Application code: workspace ID → physical database
- Partition table: workspace ID → logical schema
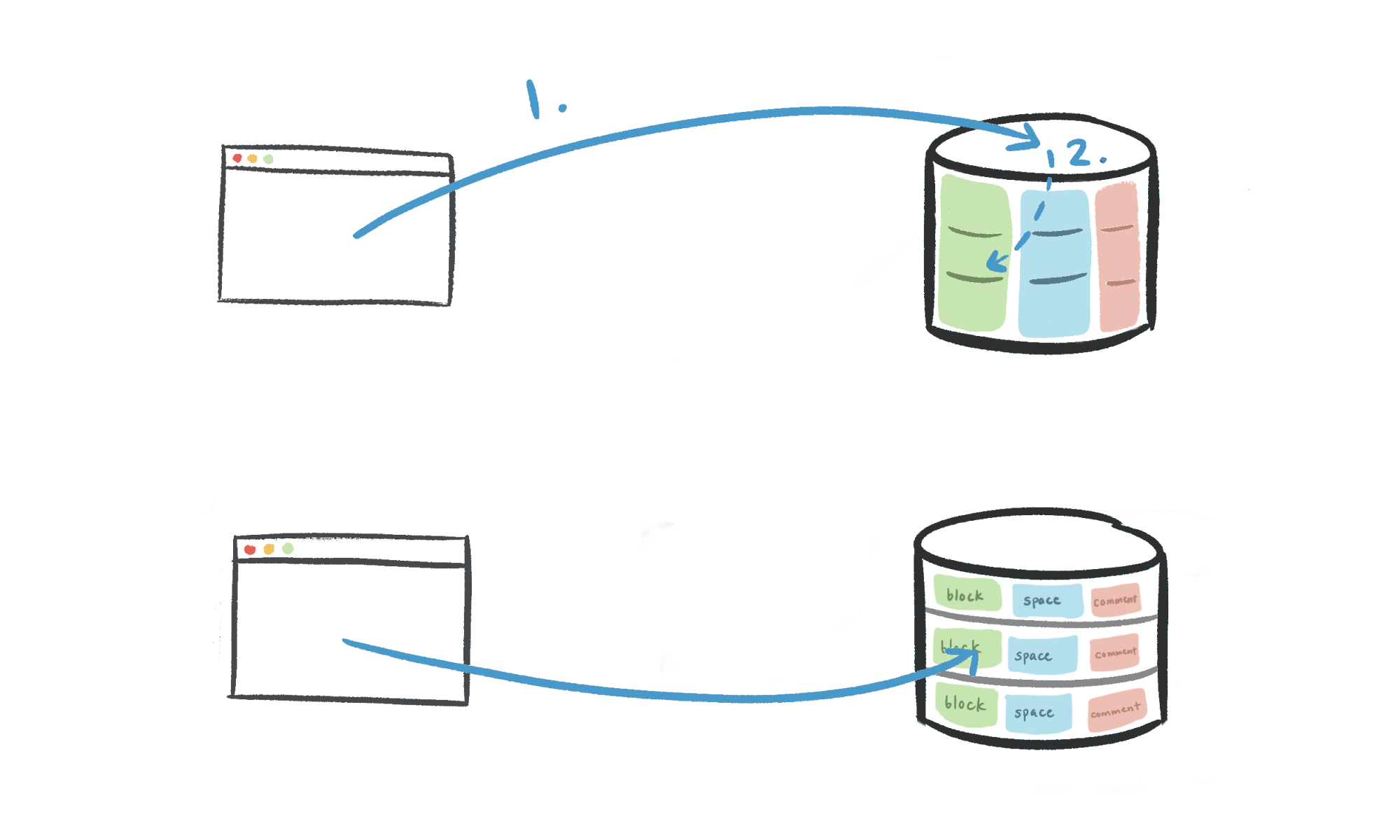
我們想要 workspace ID ⇒ logical shard 的 routing 擁有 single source of truth,所以在 Application 內部分別建立獨自的 table 去 routing。
Migrating to shards
當設計好 sharding,接下來就是實際的 Migrating,通常都是以下的步驟:
- Double-write:同時寫入新的和舊的 database
- Backfill:當 Double-write 開始執行後,把舊的資料搬到新的 database
- Verification:確認沒有錯誤。
- Switch-over:真正切換到新的 database
Double-writing with an audit log
Double-write 確保新資料寫入舊的 database 和新的 database,就算新的 database 還沒啟用喔!以下是 Double-write 執行策略選項:
- 直接同時寫兩個 Database,但是非常容易造成資料不一致
- Logical replication,用 Postgres 內建的功能去操作,但是限制上蠻大的,所以也沒有採用
- 用 Audit log 紀錄寫入的操作,然後在新的資料庫用 catch-up script 去掃過整個 audit log 寫入新的 database。
我們最終選擇第三種方式,Logical replication 建立的 Snapshot 會很難追上新的寫入量。
Backfilling old data
一旦新的資料成功寫入新的 database,我們就開始 migrate 全部資料。我們用了 96 CPU m5.24xlarge 的機器花了三天才成功 backfill production 環境!我們的 catch-up script 會檢查record versions 最終所有資料都會收斂成為一的版本。
Verifying data integrity
當成功 Migration 我們要驗證資料的正確性,實際採去的措施如下:
- Verification script:我們會連續掃過 UUID 的一些 range 去比較,由於掃過全部實在是量太大,所以我們採取隨機抽樣的方式去 Sample 檢查。
- “Dark” reads:在 migrating read queries 之前我們會加上一個 flag 同時讀取新的和舊的 database (dark reading)。我們會比較這些 records 捨棄 sharded copy 記錄過程中的差異,雖然會增加 API latency 但是也給我們無縫接軌的信心。
小補充:為了正確性我們由不同團隊寫驗證和遷移的 code。
Difficult lessons learned
最後作者給出這項大工程一些總結:
早點 Shard
雖然說我們還是小團隊的時候時常注意過早優化的問題,但是當我們意識到 database 快撐不住的時候,系統還要負責 migration 就會變得十分脆弱。
當我們決定用 workspace ID 當作 partition key 時,我們根本還沒加入這個欄位,導致我們要花更多力氣去做 sharding。
以 zero-downtime migration 為目標
Double-write throughput 是最主要最終切換 database 的 bottleneck,一旦關掉 server,catch-up script 就要完成寫入 shards 的動作。我們多花了一週的時間去優化 script,最終只花了小於 30 秒完成任務!
使用 combined primary key 而不是分離的 partition key:
現今我們的 rows 使用 composite key:包含舊 database 的 primary key id 和作為 partition key 的 space_id。因為不管如何我們都要做 full table scan,我們就把兩個 key 結合成新的 column,Application 就不需要傳入 space_ids 了。
心得
這兩篇文章含金量真的是太大了,可以說從 Notion 的最初設計到規模成長的工程過程都有詳細記錄,雖然看完真的很辛苦,但是真的長了很多不是自己去開發 Application 才會遇到的眉角,真的很精彩阿,也謝謝作者願意分享這樣的東西!