<Uber Schema-less 的系統起源>

Index
前情提要
這篇文章會被我研究到也是有些故事,由於蠻有趣的所以我就提一下,希望能夠勾起讀者的興趣!有天我在研究 Uber 的 Schemaless 系統時發現的一些趣事。
(以下是三篇文章的關鍵字,由於台灣的 Uber TW 網站掛掉了,我整理一下關鍵字,大家之後可以搜尋看看)
- <Designing Schemaless, Uber Engineering’s Scalable Datastore Using MySQL>
- <Using Triggers On Schemaless, Uber Engineering’s Datastore Using MySQL>
- <The Architecture of Schemaless, Uber Engineering’s Trip Datastore Using MySQL>
這幾篇文章都很有趣,但是我仔細檢查之下,發現他們在文中有引用到別人的想法,那我為甚麼不去研究原版呢?這樣不是概念更清楚嗎 XD?
我就找到這篇文章,也就是 <How FriendFeed uses MySQL to store schema-less data>。在我做了一些搜尋之後,發現這篇文章來頭可不小!

講完前導故事我們進入正文吧!
故事背景
一開始我們使用 MySQL 儲存所有 FriendFeed 的資料,資料成長到一個很大量的程度,我們現在儲存了 250 million 的資料,其中包含留言、好友名單、讚數之類的。
先用老招
當然,當資料庫擴張的時候,我們嘗試了許多方式來應急。例如:
隨著我們成長,這些流量讓我們很難開發新的功能,下面就是血淋淋的實例。
作者有提到,他有想到一些 operational procedures 來解決問題,例如:開一個 index 在 slave,然後交換 master 和 slave 的角色,但是這些方法太容易出錯了,尤其當我們 sharding 了 database,JOIN 已經不管用了,我們勢必要尋找新的方法來根本性的解決這些問題。
尋找新的 Infra,然後放棄
在當時的時空背景,有很多 project 都試圖解決我們遇到的問題,像是有 flexible schemas 還有 indexes on-the-fly。例如:CouchDB,但是他們都太理想化了,我根本沒有看到像我們一樣這麼大規模的 SaaS 有在用這些解決方案,實在沒有信心阿!
手動打造新的系統 Schema-less
在我們內部開會之後,我們決定自己打造一個新的儲存系統叫做 “Schema-less”,這是一種打造在 MySQL 之上的系統來滿足我們的需要,我們會在後面的篇幅跟大家介紹我們怎麼設計的。
Overview
我們的的系統儲存了一系列的資料結構,例如:JSON、Python dictionaries。如果我們需要讀取它們我們只需要一個 id,也就是常見的 16-byte UUID,在 datastore 的層級這些東西都會變成 bytes 所以我們可以根據開發新的 feature 需要去動態修改 (只要 Application Layer 知道怎麼轉回來就好)。
如果我們想要一個新的 index,就創一張新的 table,然後開一個 process asynchronous 的更新它,完全不會打亂我們線上的服務。
細節
接著我們進入細節,以下先解釋一下我們 entities table 的格式:
CREATE TABLE entities (
added_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
id BINARY(16) NOT NULL,
updated TIMESTAMP NOT NULL,
body MEDIUMBLOB,
UNIQUE KEY (id),
KEY (updated)
) ENGINE=InnoDB;
added_id 之所以會存在是因為 InnoDB 對 row 的物理儲存是依照 primary key order。AUTO_INCREMENT primary key 則是確保新的 entities 是序列化的寫入 Disk。
這對我們的服務來說是件好事,因為 FriendFeed 是依照時間來排序的,新的東西讀取會遠比舊的多。欄位中 Entity bodies 用 zlib-compressed pickled 轉成 bytes,所以說底層不用知道欄位的內容實際上是什麼。
而 indexes 則是存在分開的 table。舉例來說,我們創造一個新的 table 用來儲存 attributes。
舉例來說,一個 FriendFeed 的 entity 長的會像是:
{
"id": "71f0c4d2291844cca2df6f486e96e37c",
"user_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
"feed_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
"title": "We just launched a new backend system for FriendFeed!",
"link": "http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
"published": 1235697046,
"updated": 1235697046,
}
如果我們想要 index 上在 user_id 這個屬性, 這樣我們可以開發一個 feature 像是給定一個 user_id 列出她所有的貼文,已下會是 index table 的樣子。
CREATE TABLE index_user_id (
user_id BINARY(16) NOT NULL,
entity_id BINARY(16) NOT NULL UNIQUE,
PRIMARY KEY (user_id, entity_id)
) ENGINE=InnoDB;
我們的 datastore 會根據使用者的行為自動維護 index,下面是實際的例子:
user_id_index = friendfeed.datastore.Index(
table="index_user_id", properties=["user_id"], shard_on="user_id")
datastore = friendfeed.datastore.DataStore(
mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
indexes=[user_id_index])
new_entity = {
"id": binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"),
"user_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
"feed_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
"title": u"We just launched a new backend system for FriendFeed!",
"link": u"http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
"published": 1235697046,
"updated": 1235697046,
}
datastore.put(new_entity)
entity = datastore.get(binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"))
entity = user_id_index.get_all(datastore, user_id=binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"))
解釋一下上面這段 code,Index Class 會尋找 user_id,然後自動維護 index_user_id table。由於我們把 database sharded 了,能透過簡單的計算找出要存在哪裡,例如:entity[“user_id”] % num_shards。
你也可以 query 一個 index,像是上面 user_id_index.get_all 這個實例。datastore 可以在 Python 模擬 index_user_id table 和 entities table 的 JOIN 功能,先對所有 shard 查詢 index_user_id table 會得到一個 list entity IDs,然後再去 entities table 抓資料。
如果要增加一個 index 在 link 這個屬性上面,我們可以建造一個新的表格:
CREATE TABLE index_link (
link VARCHAR(735) NOT NULL,
entity_id BINARY(16) NOT NULL UNIQUE,
PRIMARY KEY (link, entity_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
修改一下 code 就可以把這個新的 index 包含進去:
user_id_index = friendfeed.datastore.Index(
table="index_user_id", properties=["user_id"], shard_on="user_id")
link_index = friendfeed.datastore.Index(
table="index_link", properties=["link"], shard_on="link")
datastore = friendfeed.datastore.DataStore(
mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
indexes=[user_id_index, link_index])
甚至系統還在上線,我們也能夠執行一些腳本去 asynchronously 讀取 index。
Consistency and Atomicity
雖然上面提供了很美好的解法,但是我們有個問題,由於東西全面分散了,我們要怎麼管理一致性? 舉例來說:如果我們寫完所有的 index 之前就 crash 了,這就是個大問題!
打造一個 transaction protocol 雖然很吸引人,但是我們真的希望系統可以簡單就好,所以我們採取了以下的取捨。
- property bag 和 entities table 是中心化的
- Indexes 可能不會反映真實的 entity values
結論就是當寫入一個新的 entity,會依照下面的步驟:
- 要寫入 entity 時用 ACID 的標準寫入 entities table
- 把 index 寫入所有的 shard 上的 index tables
當我們從 index tables 讀取資料的時候,我們知道很可能東西是不正確的,舉例來說:還停留在上一個階段,因為上次寫到一半 Application Server 掛點了。為了正確性,我們採取以下步驟:
- 從 index tables 讀取 entity_id
- 從 entities table 讀取 entities 用上面的到的 IDs
- 在應用程式中 Filter 掉不正確的資料
Performance
我們優化了 primary indexes,對於結果我們常滿意,view latency 有戲劇性的轉變。

除此之外,穩定性也非常好,這是最近 24 小時的 peaks 變化圖:
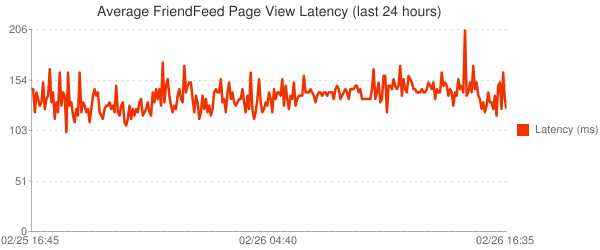
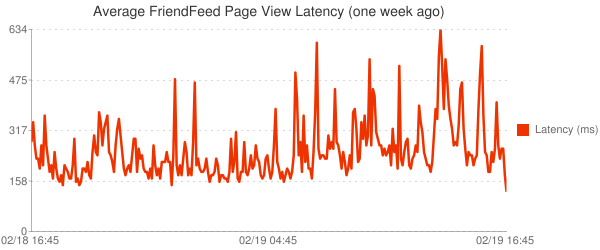
最後用一週的時間來分析結果
感想
這篇文章是 2009 年寫的,當時可不像現在有那麼多的可靠又成熟資料庫可以選擇,甚至連 NoSQL 在大眾市場都不算成熟,但是該解決的問題還是要解決。
我想不論在什麼時代都一定會有一些很可靠的舊技術和很搶眼的新技術,對於維護真正的服務的人往往都要做出選擇,每讀一篇這種在當時第一線的人做的決定和思考,讓我學習到很多眉眉角角。說穿了這些東西我想講講大家都會,但是能夠構思的多全面,卻又是另一個哲學問題!感謝作者給我的感動。